Age Detection¶
This tutorial is available as an IPython notebook at malaya-speech/example/age-detection.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
Dataset¶
Trained on Age column from Common Voice Mozilla Dataset with augmented noises, https://commonvoice.mozilla.org/
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
[2]:
y, sr = malaya_speech.load('speech/video/The-Singaporean-White-Boy.wav')
len(y), sr
[2]:
(1634237, 16000)
[3]:
# just going to take 30 seconds
y = y[:sr * 30]
[4]:
import IPython.display as ipd
ipd.Audio(y, rate = sr)
[4]:
This audio extracted from https://www.youtube.com/watch?v=HylaY5e1awo&t=2s
Supported age¶
[5]:
malaya_speech.age_detection.labels
[5]:
['teens',
'twenties',
'thirties',
'fourties',
'fifties',
'sixties',
'seventies',
'eighties',
'nineties',
'not an age']
List available deep model¶
[6]:
malaya_speech.age_detection.available_model()
INFO:root:last accuracy during training session before early stopping.
[6]:
| Size (MB) | Quantized Size (MB) | Accuracy | |
|---|---|---|---|
| vggvox-v2 | 30.9 | 7.92 | 0.57523 |
| deep-speaker | 96.9 | 24.40 | 0.58584 |
Load deep model¶
def deep_model(model: str = 'vggvox-v2', quantized: bool = False, **kwargs):
"""
Load age detection deep model.
Parameters
----------
model : str, optional (default='vggvox-v2')
Model architecture supported. Allowed values:
* ``'vggvox-v2'`` - finetuned VGGVox V2.
* ``'deep-speaker'`` - finetuned Deep Speaker.
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
Returns
-------
result : malaya_speech.supervised.classification.load function
"""
[7]:
vggvox_v2 = malaya_speech.age_detection.deep_model(model = 'vggvox-v2')
deep_speaker = malaya_speech.age_detection.deep_model(model = 'deep-speaker')
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:66: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:66: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:68: The name tf.GraphDef is deprecated. Please use tf.compat.v1.GraphDef instead.
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:68: The name tf.GraphDef is deprecated. Please use tf.compat.v1.GraphDef instead.
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:61: The name tf.InteractiveSession is deprecated. Please use tf.compat.v1.InteractiveSession instead.
WARNING:tensorflow:From /Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/utils/__init__.py:61: The name tf.InteractiveSession is deprecated. Please use tf.compat.v1.InteractiveSession instead.
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/tensorflow_core/python/client/session.py:1750: UserWarning: An interactive session is already active. This can cause out-of-memory errors in some cases. You must explicitly call `InteractiveSession.close()` to release resources held by the other session(s).
warnings.warn('An interactive session is already active. This can '
Load Quantized deep model¶
To load 8-bit quantized model, simply pass quantized = True, default is False.
We can expect slightly accuracy drop from quantized model, and not necessary faster than normal 32-bit float model, totally depends on machine.
[8]:
quantized_vggvox_v2 = malaya_speech.age_detection.deep_model(model = 'vggvox-v2', quantized = True)
WARNING:root:Load quantized model will cause accuracy drop.
How to classify age in an audio sample¶
So we are going to use VAD to help us. Instead we are going to classify as a whole sample, we chunk it into multiple small samples and classify it.
[9]:
vad = malaya_speech.vad.deep_model(model = 'vggvox-v2')
[10]:
%%time
frames = list(malaya_speech.utils.generator.frames(y, 30, sr))
CPU times: user 2.47 ms, sys: 123 µs, total: 2.59 ms
Wall time: 2.63 ms
[11]:
p = Pipeline()
pipeline = (
p.batching(5)
.foreach_map(vad.predict)
.flatten()
)
p.visualize()
[11]:
[12]:
%%time
result = p.emit(frames)
result.keys()
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/librosa/core/spectrum.py:224: UserWarning: n_fft=512 is too small for input signal of length=480
n_fft, y.shape[-1]
CPU times: user 32.7 s, sys: 5.6 s, total: 38.3 s
Wall time: 7.55 s
[12]:
dict_keys(['batching', 'predict', 'flatten'])
[13]:
frames_vad = [(frame, result['flatten'][no]) for no, frame in enumerate(frames)]
grouped_vad = malaya_speech.utils.group.group_frames(frames_vad)
grouped_vad = malaya_speech.utils.group.group_frames_threshold(grouped_vad, threshold_to_stop = 0.3)
[14]:
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, figsize = (15, 3))
<Figure size 1500x300 with 1 Axes>
[15]:
p_vggvox_v2 = Pipeline()
pipeline = (
p_vggvox_v2.foreach_map(vggvox_v2)
.flatten()
)
p_vggvox_v2.visualize()
[15]:
[16]:
p_deep_speaker = Pipeline()
pipeline = (
p_deep_speaker.foreach_map(deep_speaker)
.flatten()
)
p_deep_speaker.visualize()
[16]:
[17]:
%%time
samples_vad = [g[0] for g in grouped_vad]
result_vggvox_v2 = p_vggvox_v2.emit(samples_vad)
result_vggvox_v2.keys()
CPU times: user 4.64 s, sys: 841 ms, total: 5.48 s
Wall time: 1.4 s
[17]:
dict_keys(['age-detection', 'flatten'])
[18]:
%%time
samples_vad = [g[0] for g in grouped_vad]
result_deep_speaker = p_deep_speaker.emit(samples_vad)
result_deep_speaker.keys()
CPU times: user 5.07 s, sys: 797 ms, total: 5.86 s
Wall time: 1.53 s
[18]:
dict_keys(['age-detection', 'flatten'])
[19]:
samples_vad_vggvox_v2 = [(frame, result_vggvox_v2['flatten'][no]) for no, frame in enumerate(samples_vad)]
samples_vad_vggvox_v2
[19]:
[(<malaya_speech.model.frame.Frame at 0x147039490>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2a90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x146fe2850>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x146fe2950>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045a50>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045a90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045ad0>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045b50>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045b10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045a10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045bd0>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045c10>, 'seventies'),
(<malaya_speech.model.frame.Frame at 0x147045c50>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045cd0>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045c90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045d50>, 'thirties'),
(<malaya_speech.model.frame.Frame at 0x147045d90>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045d10>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045e10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045dd0>, 'teens')]
[20]:
samples_vad_deep_speaker = [(frame, result_deep_speaker['flatten'][no]) for no, frame in enumerate(samples_vad)]
samples_vad_deep_speaker
[20]:
[(<malaya_speech.model.frame.Frame at 0x147039490>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2a90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2850>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x146fe2950>, 'fifties'),
(<malaya_speech.model.frame.Frame at 0x147045a50>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045a90>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045ad0>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045b50>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045b10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045a10>, 'thirties'),
(<malaya_speech.model.frame.Frame at 0x147045b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045bd0>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045c10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045c50>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045cd0>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045c90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045d50>, 'thirties'),
(<malaya_speech.model.frame.Frame at 0x147045d90>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045d10>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045e10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045dd0>, 'teens')]
[21]:
import matplotlib.pyplot as plt
[22]:
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(samples_vad_vggvox_v2,
'age detection vggvox v2', ax = ax[1])
malaya_speech.extra.visualization.plot_classification(samples_vad_deep_speaker,
'age detection deep speaker', ax = ax[2])
fig.tight_layout()
plt.show()
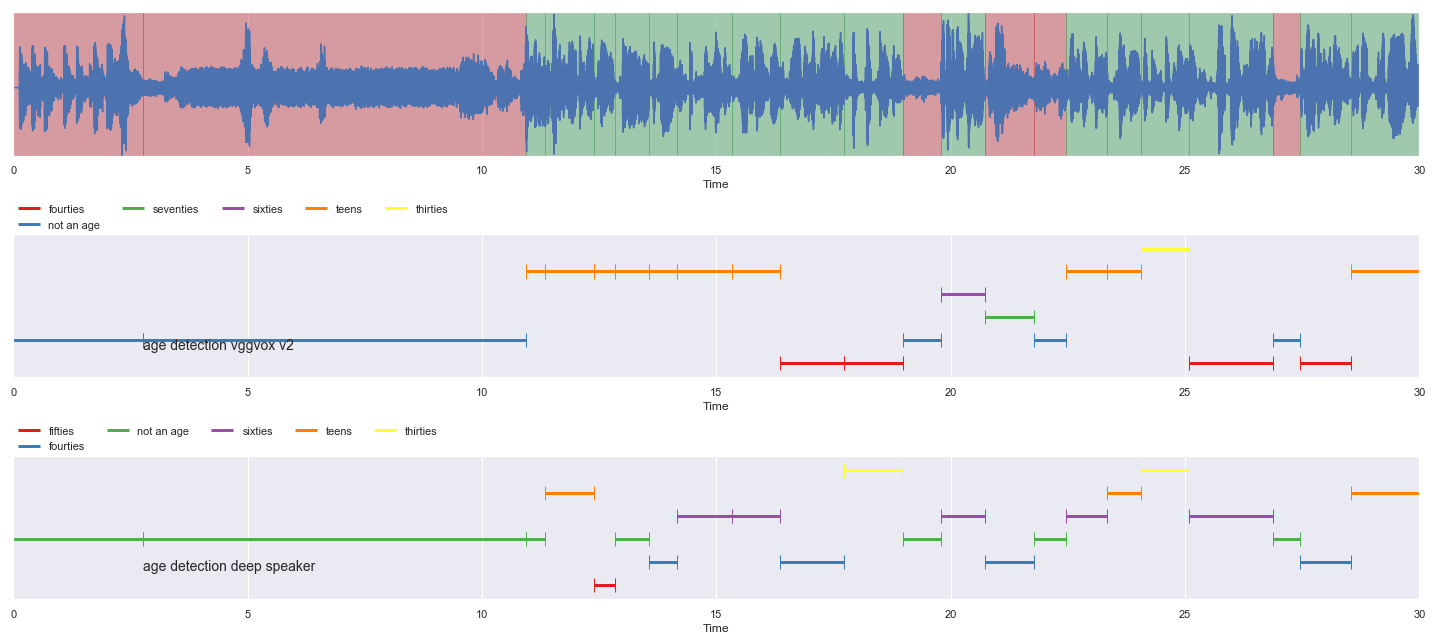
[23]:
p_quantized_vggvox_v2 = Pipeline()
pipeline = (
p_quantized_vggvox_v2.foreach_map(quantized_vggvox_v2)
.flatten()
)
p_quantized_vggvox_v2.visualize()
[23]:
[24]:
%%time
samples_vad = [g[0] for g in grouped_vad]
result_quantized_vggvox_v2 = p_quantized_vggvox_v2.emit(samples_vad)
result_quantized_vggvox_v2.keys()
CPU times: user 4.75 s, sys: 935 ms, total: 5.68 s
Wall time: 1.33 s
[24]:
dict_keys(['age-detection', 'flatten'])
[25]:
samples_vad_quantized_vggvox_v2 = [(frame, result_quantized_vggvox_v2['flatten'][no]) for no, frame in enumerate(samples_vad)]
samples_vad_quantized_vggvox_v2
[25]:
[(<malaya_speech.model.frame.Frame at 0x147039490>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x146fe2a90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x146fe2850>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x146fe2950>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045a50>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045a90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045ad0>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045b50>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045b10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045a10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045b90>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045bd0>, 'sixties'),
(<malaya_speech.model.frame.Frame at 0x147045c10>, 'seventies'),
(<malaya_speech.model.frame.Frame at 0x147045c50>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045cd0>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045c90>, 'teens'),
(<malaya_speech.model.frame.Frame at 0x147045d50>, 'thirties'),
(<malaya_speech.model.frame.Frame at 0x147045d90>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045d10>, 'not an age'),
(<malaya_speech.model.frame.Frame at 0x147045e10>, 'fourties'),
(<malaya_speech.model.frame.Frame at 0x147045dd0>, 'teens')]
[26]:
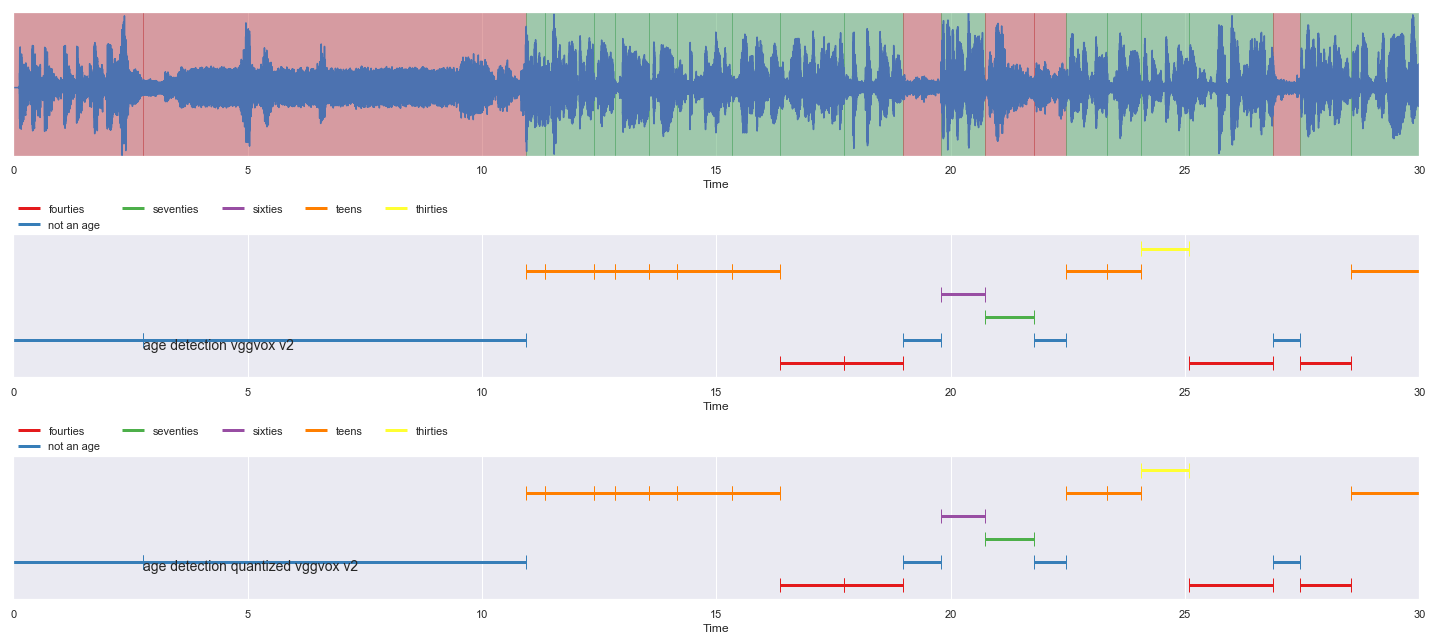
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(samples_vad_vggvox_v2,
'age detection vggvox v2', ax = ax[1])
malaya_speech.extra.visualization.plot_classification(samples_vad_quantized_vggvox_v2,
'age detection quantized vggvox v2', ax = ax[2])
fig.tight_layout()
plt.show()
Reference¶
The Singaporean White Boy - The Shan and Rozz Show: EP7, https://www.youtube.com/watch?v=HylaY5e1awo&t=2s&ab_channel=Clicknetwork
Common Voice dataset, https://commonvoice.mozilla.org/
[ ]: