
Force Alignment using CTC
Contents
Force Alignment using CTC#
Forced alignment is a technique to take an orthographic transcription of an audio file and generate a time-aligned version. In this example, I am going to use Malay and Singlish CTC models.
This tutorial is available as an IPython notebook at malaya-speech/example/force-alignment-ctc.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
import IPython.display as ipd
import matplotlib.pyplot as plt
from malaya_speech.utils.aligner import plot_alignments
List available CTC models#
[2]:
malaya_speech.force_alignment.available_ctc()
[2]:
| Size (MB) | Quantized Size (MB) | WER | CER | WER-LM | CER-LM | Language | |
|---|---|---|---|---|---|---|---|
| hubert-conformer-tiny | 36.6 | 10.3 | 0.335968 | 0.0882573 | 0.199227 | 0.0635223 | [malay] |
| hubert-conformer | 115 | 31.1 | 0.238714 | 0.0608998 | 0.141479 | 0.0450751 | [malay] |
| hubert-conformer-large | 392 | 100 | 0.220314 | 0.054927 | 0.128006 | 0.0385329 | [malay] |
| hubert-conformer-large-3mixed | 392 | 100 | 0.241126 | 0.0787939 | 0.132761 | 0.057482 | [malay, singlish, mandarin] |
| best-rq-conformer-tiny | 36.6 | 10.3 | 0.319291 | 0.078988 | 0.179582 | 0.055521 | [malay] |
| best-rq-conformer | 115 | 31.1 | 0.253678 | 0.0658045 | 0.154206 | 0.0482278 | [malay] |
| best-rq-conformer-large | 392 | 100 | 0.234651 | 0.0601605 | 0.130082 | 0.044521 | [malay] |
Load CTC Aligner model#
def deep_ctc(
model: str = 'hubert-conformer', quantized: bool = False, **kwargs
):
"""
Load Encoder-CTC ASR model.
Parameters
----------
model : str, optional (default='hubert-conformer')
Model architecture supported. Allowed values:
* ``'hubert-conformer-tiny'`` - Finetuned HuBERT Conformer TINY.
* ``'hubert-conformer'`` - Finetuned HuBERT Conformer.
* ``'hubert-conformer-large'`` - Finetuned HuBERT Conformer LARGE.
* ``'hubert-conformer-large-3mixed'`` - Finetuned HuBERT Conformer LARGE for (Malay + Singlish + Mandarin) languages.
* ``'best-rq-conformer-tiny'`` - Finetuned BEST-RQ Conformer TINY.
* ``'best-rq-conformer'`` - Finetuned BEST-RQ Conformer.
* ``'best-rq-conformer-large'`` - Finetuned BEST-RQ Conformer LARGE.
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
Returns
-------
result : malaya_speech.model.wav2vec.Wav2Vec2_Aligner class
"""
[3]:
model = malaya_speech.force_alignment.deep_ctc(model = 'hubert-conformer')
[4]:
mixed_model = malaya_speech.force_alignment.deep_ctc(model = 'hubert-conformer-large-3mixed')
Load sample#
Malay samples#
[5]:
malay1, sr = malaya_speech.load('speech/example-speaker/shafiqah-idayu.wav')
malay2, sr = malaya_speech.load('speech/example-speaker/haqkiem.wav')
[6]:
texts = ['nama saya shafiqah idayu',
'sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang']
[7]:
ipd.Audio(malay2, rate = sr)
[7]:
Singlish samples#
[8]:
import json
import os
from glob import glob
with open('speech/imda/output.json') as fopen:
data = json.load(fopen)
data
[8]:
{'221931702.WAV': 'wantan mee is a traditional local cuisine',
'221931818.WAV': 'ahmad khan adelene wee chin suan and robert ibbetson',
'221931727.WAV': 'saravanan gopinathan george yeo yong boon and tay kheng soon'}
[9]:
wavs = glob('speech/imda/*.WAV')
wavs
[9]:
['speech/imda/221931727.WAV',
'speech/imda/221931818.WAV',
'speech/imda/221931702.WAV']
[10]:
y, sr = malaya_speech.load(wavs[0])
[11]:
ipd.Audio(y, rate = sr)
[11]:
Predict#
def predict(self, input, transcription: str, sample_rate: int = 16000):
"""
Transcribe input, will return a string.
Parameters
----------
input: np.array
np.array or malaya_speech.model.frame.Frame.
transcription: str
transcription of input audio.
sample_rate: int, optional (default=16000)
sample rate for `input`.
Returns
-------
result: Dict[chars_alignment, words_alignment, alignment]
"""
Predict Malay#
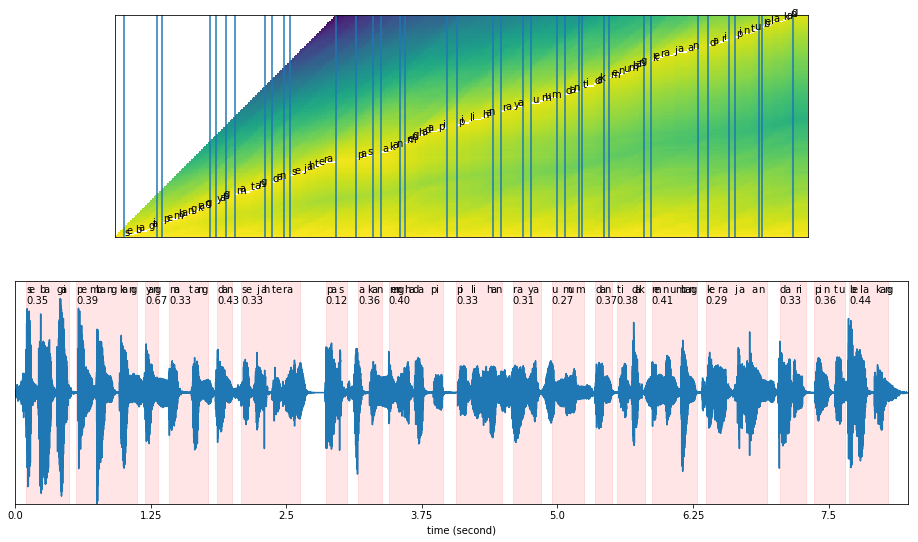
Our original text is: ‘sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang’
[12]:
results = model.predict(malay2, texts[1])
[13]:
results.keys()
[13]:
dict_keys(['chars_alignment', 'words_alignment', 'alignment'])
[14]:
results['words_alignment']
[14]:
[{'text': 'sebagai',
'start': 0.10013914233576643,
'end': 0.5006957116788322,
'start_t': 5,
'end_t': 25,
'score': 0.34897278547494653},
{'text': 'pembangkang',
'start': 0.560779197080292,
'end': 1.121558394160584,
'start_t': 28,
'end_t': 56,
'score': 0.3905156957775239},
{'text': 'yang',
'start': 1.2016697080291971,
'end': 1.321836678832117,
'start_t': 60,
'end_t': 66,
'score': 0.6657784879221825},
{'text': 'matang',
'start': 1.4219758211678832,
'end': 1.7824767335766425,
'start_t': 71,
'end_t': 89,
'score': 0.3326612651595139},
{'text': 'dan',
'start': 1.8625880474452556,
'end': 2.002782846715329,
'start_t': 93,
'end_t': 100,
'score': 0.4283144218597406},
{'text': 'sejahtera',
'start': 2.0828941605839417,
'end': 2.6236455291970806,
'start_t': 104,
'end_t': 131,
'score': 0.3320172760391689},
{'text': 'pas',
'start': 2.86397947080292,
'end': 3.064257755474453,
'start_t': 143,
'end_t': 153,
'score': 0.11881501389760815},
{'text': 'akan',
'start': 3.164396897810219,
'end': 3.3847030109489054,
'start_t': 158,
'end_t': 169,
'score': 0.3623452024151932},
{'text': 'menghadapi',
'start': 3.444786496350365,
'end': 3.945482208029197,
'start_t': 172,
'end_t': 197,
'score': 0.39888698593031147},
{'text': 'pilihan',
'start': 4.065649178832117,
'end': 4.486233576642336,
'start_t': 203,
'end_t': 224,
'score': 0.3326954983691173},
{'text': 'raya',
'start': 4.586372718978103,
'end': 4.846734489051095,
'start_t': 229,
'end_t': 242,
'score': 0.30750036704822425},
{'text': 'umum',
'start': 4.946873631386862,
'end': 5.247291058394161,
'start_t': 247,
'end_t': 262,
'score': 0.26633543572989365},
{'text': 'dan',
'start': 5.347430200729927,
'end': 5.507652828467154,
'start_t': 267,
'end_t': 275,
'score': 0.3746163249118229},
{'text': 'tidak',
'start': 5.54770848540146,
'end': 5.808070255474453,
'start_t': 277,
'end_t': 290,
'score': 0.3845034150083502},
{'text': 'menumbang',
'start': 5.868153740875913,
'end': 6.288738138686131,
'start_t': 293,
'end_t': 314,
'score': 0.4133131617679174},
{'text': 'kerajaan',
'start': 6.368849452554745,
'end': 6.9296286496350366,
'start_t': 318,
'end_t': 346,
'score': 0.2856007218372845},
{'text': 'dari',
'start': 7.049795620437957,
'end': 7.290129562043796,
'start_t': 352,
'end_t': 364,
'score': 0.3331856578826829},
{'text': 'pintu',
'start': 7.370240875912409,
'end': 7.650630474452555,
'start_t': 368,
'end_t': 382,
'score': 0.3570024328726298},
{'text': 'belakang',
'start': 7.690686131386862,
'end': 8.05118704379562,
'start_t': 384,
'end_t': 402,
'score': 0.4434706668115288}]
Plot alignment#
def plot_alignments(
alignment,
subs_alignment,
words_alignment,
waveform,
separator: str = ' ',
sample_rate: int = 16000,
figsize: tuple = (16, 9),
plot_score_char: bool = False,
plot_score_word: bool = True,
):
"""
plot alignment.
Parameters
----------
alignment: np.array
usually `alignment` output.
subs_alignment: list
usually `chars_alignment` or `subwords_alignment` output.
words_alignment: list
usually `words_alignment` output.
waveform: np.array
input audio.
separator: str, optional (default=' ')
separator between words, only useful if `subs_alignment` is character based.
sample_rate: int, optional (default=16000)
figsize: tuple, optional (default=(16, 9))
figure size for matplotlib `figsize`.
plot_score_char: bool, optional (default=False)
plot score on top of character plots.
plot_score_word: bool, optional (default=True)
plot score on top of word plots.
"""
[16]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = malay2,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
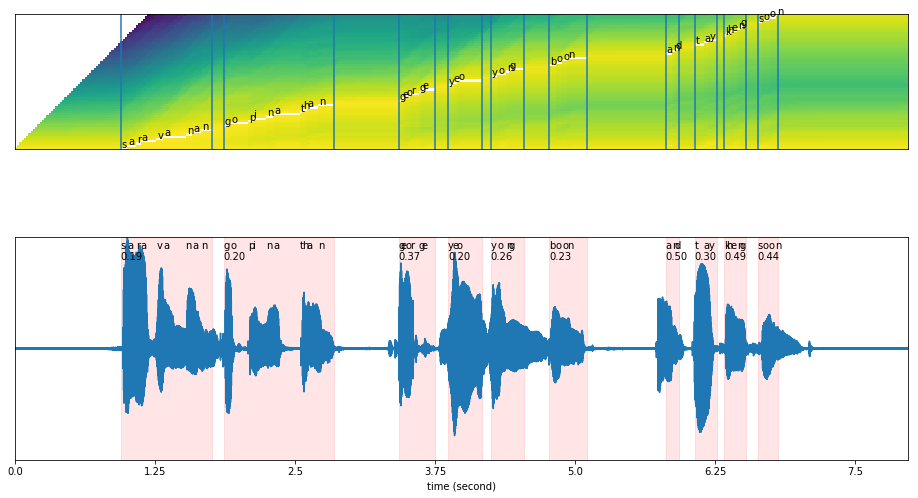
Predict Singlish#
Our original text is: ‘saravanan gopinathan george yeo yong boon and tay kheng soon’
[17]:
results = mixed_model.predict(y, data[os.path.split(wavs[0])[1]])
[18]:
results.keys()
[18]:
dict_keys(['chars_alignment', 'words_alignment', 'alignment'])
[19]:
results['words_alignment']
[19]:
[{'text': 'saravanan',
'start': 0.941180904522613,
'end': 1.7622110552763819,
'start_t': 47,
'end_t': 88,
'score': 0.18763287488331273},
{'text': 'gopinathan',
'start': 1.8623366834170854,
'end': 2.84356783919598,
'start_t': 93,
'end_t': 142,
'score': 0.20010886631289232},
{'text': 'george',
'start': 3.4242964824120605,
'end': 3.7446984924623115,
'start_t': 171,
'end_t': 187,
'score': 0.37452898187242656},
{'text': 'yeo',
'start': 3.864849246231156,
'end': 4.1652261306532665,
'start_t': 193,
'end_t': 208,
'score': 0.1993353687451018},
{'text': 'yong',
'start': 4.2453266331658295,
'end': 4.54570351758794,
'start_t': 212,
'end_t': 227,
'score': 0.2626648187659538},
{'text': 'boon',
'start': 4.765979899497488,
'end': 5.10640703517588,
'start_t': 238,
'end_t': 255,
'score': 0.23324423677917153},
{'text': 'and',
'start': 5.807286432160804,
'end': 5.927437185929648,
'start_t': 290,
'end_t': 296,
'score': 0.4999442895259972},
{'text': 'tay',
'start': 6.067613065326634,
'end': 6.26786432160804,
'start_t': 303,
'end_t': 313,
'score': 0.2983391344595209},
{'text': 'kheng',
'start': 6.327939698492463,
'end': 6.528190954773869,
'start_t': 316,
'end_t': 326,
'score': 0.4886619269919623},
{'text': 'soon',
'start': 6.628316582914573,
'end': 6.80854271356784,
'start_t': 331,
'end_t': 340,
'score': 0.4431956807809488}]
[20]:
results['chars_alignment']
[20]:
[{'text': 's',
'start': 0.941180904522613,
'end': 1.0012562814070352,
'start_t': 47,
'end_t': 50,
'score': 0.33196959897144457},
{'text': 'a',
'start': 1.0012562814070352,
'end': 1.081356783919598,
'start_t': 50,
'end_t': 54,
'score': 0.23288598657160595},
{'text': 'r',
'start': 1.081356783919598,
'end': 1.1214070351758794,
'start_t': 54,
'end_t': 56,
'score': 0.39886018635627857},
{'text': 'a',
'start': 1.1214070351758794,
'end': 1.2615829145728643,
'start_t': 56,
'end_t': 63,
'score': 0.11159036000876765},
{'text': 'v',
'start': 1.2615829145728643,
'end': 1.3216582914572865,
'start_t': 63,
'end_t': 66,
'score': 0.31265960138630633},
{'text': 'a',
'start': 1.3216582914572865,
'end': 1.5219095477386935,
'start_t': 66,
'end_t': 76,
'score': 0.07917934668213271},
{'text': 'n',
'start': 1.5219095477386935,
'end': 1.5819849246231157,
'start_t': 76,
'end_t': 79,
'score': 0.32596125211928234},
{'text': 'a',
'start': 1.5819849246231157,
'end': 1.6620854271356784,
'start_t': 79,
'end_t': 83,
'score': 0.2408168316012087},
{'text': 'n',
'start': 1.6620854271356784,
'end': 1.7622110552763819,
'start_t': 83,
'end_t': 88,
'score': 0.10314377609964123},
{'text': ' ',
'start': 1.7622110552763819,
'end': 1.8623366834170854,
'start_t': 88,
'end_t': 93,
'score': 0.19303946495554644},
{'text': 'g',
'start': 1.8623366834170854,
'end': 1.9224120603015076,
'start_t': 93,
'end_t': 96,
'score': 0.3320287664839567},
{'text': 'o',
'start': 1.9224120603015076,
'end': 2.0826130653266333,
'start_t': 96,
'end_t': 104,
'score': 0.12450930476255619},
{'text': 'p',
'start': 2.0826130653266333,
'end': 2.1226633165829147,
'start_t': 104,
'end_t': 106,
'score': 0.4991674423220821},
{'text': 'i',
'start': 2.1226633165829147,
'end': 2.2428140703517587,
'start_t': 106,
'end_t': 112,
'score': 0.16561626394711962},
{'text': 'n',
'start': 2.2428140703517587,
'end': 2.302889447236181,
'start_t': 112,
'end_t': 115,
'score': 0.32914326589196685},
{'text': 'a',
'start': 2.302889447236181,
'end': 2.5431909547738694,
'start_t': 115,
'end_t': 127,
'score': 0.08254873755678713},
{'text': 't',
'start': 2.5431909547738694,
'end': 2.56321608040201,
'start_t': 127,
'end_t': 128,
'score': 0.9963043928146362},
{'text': 'h',
'start': 2.56321608040201,
'end': 2.6032663316582916,
'start_t': 128,
'end_t': 130,
'score': 0.4278713763107092},
{'text': 'a',
'start': 2.6032663316582916,
'end': 2.703391959798995,
'start_t': 130,
'end_t': 135,
'score': 0.1991872191431391},
{'text': 'n',
'start': 2.703391959798995,
'end': 2.84356783919598,
'start_t': 135,
'end_t': 142,
'score': 0.14216333627763245},
{'text': ' ',
'start': 2.84356783919598,
'end': 3.4242964824120605,
'start_t': 142,
'end_t': 171,
'score': 0.03384907492310512},
{'text': 'g',
'start': 3.4242964824120605,
'end': 3.4443216080402013,
'start_t': 171,
'end_t': 172,
'score': 0.9997904896736145},
{'text': 'e',
'start': 3.4443216080402013,
'end': 3.4843718592964823,
'start_t': 172,
'end_t': 174,
'score': 0.4971865127017847},
{'text': 'o',
'start': 3.4843718592964823,
'end': 3.5244221105527638,
'start_t': 174,
'end_t': 176,
'score': 0.4999451935553722},
{'text': 'r',
'start': 3.5244221105527638,
'end': 3.6045226130653267,
'start_t': 176,
'end_t': 180,
'score': 0.249802276505746},
{'text': 'g',
'start': 3.6045226130653267,
'end': 3.6245477386934675,
'start_t': 180,
'end_t': 181,
'score': 0.9996540546417236},
{'text': 'e',
'start': 3.6245477386934675,
'end': 3.7446984924623115,
'start_t': 181,
'end_t': 187,
'score': 0.1665911078510315},
{'text': ' ',
'start': 3.7446984924623115,
'end': 3.864849246231156,
'start_t': 187,
'end_t': 193,
'score': 0.16663597027596586},
{'text': 'y',
'start': 3.864849246231156,
'end': 3.9048994974874374,
'start_t': 193,
'end_t': 195,
'score': 0.49971494127885274},
{'text': 'e',
'start': 3.9048994974874374,
'end': 3.944949748743719,
'start_t': 195,
'end_t': 197,
'score': 0.49675673340179916},
{'text': 'o',
'start': 3.944949748743719,
'end': 4.1652261306532665,
'start_t': 197,
'end_t': 208,
'score': 0.0906442892559294},
{'text': ' ',
'start': 4.1652261306532665,
'end': 4.2453266331658295,
'start_t': 208,
'end_t': 212,
'score': 0.2465362399817041},
{'text': 'y',
'start': 4.2453266331658295,
'end': 4.305402010050251,
'start_t': 212,
'end_t': 215,
'score': 0.33105246226827195},
{'text': 'o',
'start': 4.305402010050251,
'end': 4.385502512562814,
'start_t': 215,
'end_t': 219,
'score': 0.242510870100768},
{'text': 'n',
'start': 4.385502512562814,
'end': 4.4055276381909545,
'start_t': 219,
'end_t': 220,
'score': 0.9935130476951599},
{'text': 'g',
'start': 4.4055276381909545,
'end': 4.54570351758794,
'start_t': 220,
'end_t': 227,
'score': 0.14046548094089426},
{'text': ' ',
'start': 4.54570351758794,
'end': 4.765979899497488,
'start_t': 227,
'end_t': 238,
'score': 0.0904210697530431},
{'text': 'b',
'start': 4.765979899497488,
'end': 4.82605527638191,
'start_t': 238,
'end_t': 241,
'score': 0.3321694930413363},
{'text': 'o',
'start': 4.82605527638191,
'end': 4.886130653266331,
'start_t': 241,
'end_t': 244,
'score': 0.33324974775749916},
{'text': 'o',
'start': 4.886130653266331,
'end': 4.926180904522613,
'start_t': 244,
'end_t': 246,
'score': 0.4852087199688646},
{'text': 'n',
'start': 4.926180904522613,
'end': 5.10640703517588,
'start_t': 246,
'end_t': 255,
'score': 0.1109418736568534},
{'text': ' ',
'start': 5.10640703517588,
'end': 5.807286432160804,
'start_t': 255,
'end_t': 290,
'score': 0.028484645911766353},
{'text': 'a',
'start': 5.807286432160804,
'end': 5.867361809045226,
'start_t': 290,
'end_t': 293,
'score': 0.3333034912754038},
{'text': 'n',
'start': 5.867361809045226,
'end': 5.887386934673367,
'start_t': 293,
'end_t': 294,
'score': 0.9999722838401794},
{'text': 'd',
'start': 5.887386934673367,
'end': 5.927437185929648,
'start_t': 294,
'end_t': 296,
'score': 0.4998914897447962},
{'text': ' ',
'start': 5.927437185929648,
'end': 6.067613065326634,
'start_t': 296,
'end_t': 303,
'score': 0.1427545888090139},
{'text': 't',
'start': 6.067613065326634,
'end': 6.1477135678391965,
'start_t': 303,
'end_t': 307,
'score': 0.24978102744329242},
{'text': 'a',
'start': 6.1477135678391965,
'end': 6.187763819095477,
'start_t': 307,
'end_t': 309,
'score': 0.4960425198122112},
{'text': 'y',
'start': 6.187763819095477,
'end': 6.26786432160804,
'start_t': 309,
'end_t': 313,
'score': 0.24804554879940433},
{'text': ' ',
'start': 6.26786432160804,
'end': 6.327939698492463,
'start_t': 313,
'end_t': 316,
'score': 0.3321625789006593},
{'text': 'k',
'start': 6.327939698492463,
'end': 6.347964824120603,
'start_t': 316,
'end_t': 317,
'score': 0.9986454844474792},
{'text': 'h',
'start': 6.347964824120603,
'end': 6.3880150753768845,
'start_t': 317,
'end_t': 319,
'score': 0.44590100648667685},
{'text': 'e',
'start': 6.3880150753768845,
'end': 6.448090452261306,
'start_t': 319,
'end_t': 322,
'score': 0.33290648460548466},
{'text': 'n',
'start': 6.448090452261306,
'end': 6.4681155778894475,
'start_t': 322,
'end_t': 323,
'score': 0.9983878135681152},
{'text': 'g',
'start': 6.4681155778894475,
'end': 6.528190954773869,
'start_t': 323,
'end_t': 326,
'score': 0.3330215017047404},
{'text': ' ',
'start': 6.528190954773869,
'end': 6.628316582914573,
'start_t': 326,
'end_t': 331,
'score': 0.19998093843787793},
{'text': 's',
'start': 6.628316582914573,
'end': 6.668366834170854,
'start_t': 331,
'end_t': 333,
'score': 0.4994238019091495},
{'text': 'o',
'start': 6.668366834170854,
'end': 6.728442211055277,
'start_t': 333,
'end_t': 336,
'score': 0.3324198524158745},
{'text': 'o',
'start': 6.728442211055277,
'end': 6.788517587939698,
'start_t': 336,
'end_t': 339,
'score': 0.33211205403430194},
{'text': 'n',
'start': 6.788517587939698,
'end': 6.80854271356784,
'start_t': 339,
'end_t': 340,
'score': 0.9963178038597107}]
[21]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = y,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
What if we give wrong transcription?#
[22]:
results = mixed_model.predict(y, 'husein sangat comel')
[23]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = y,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
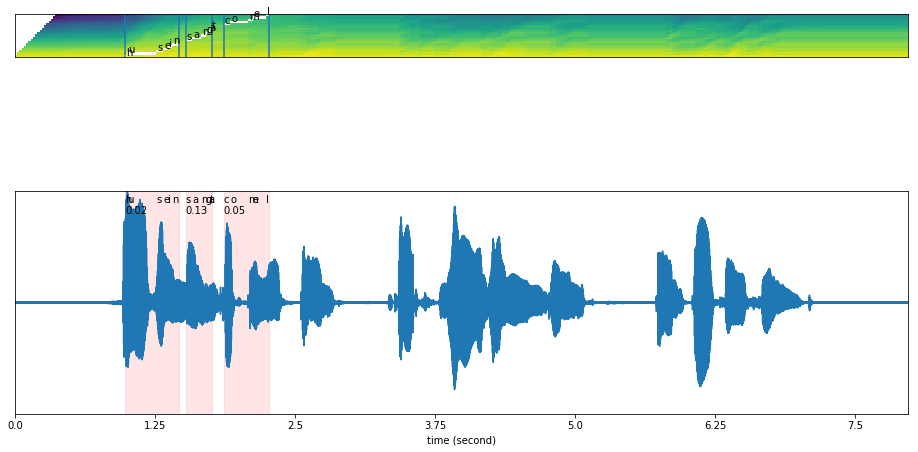
The text output not able to align, and returned scores very low.