
Speech-to-Text RNNT web inference using Gradio
Contents
Speech-to-Text RNNT web inference using Gradio#
Encoder model + RNNT loss web inference using Gradio
This tutorial is available as an IPython notebook at malaya-speech/example/stt-transducer-gradio.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
List available RNNT model#
[2]:
malaya_speech.stt.available_transducer()
[2]:
| Size (MB) | Quantized Size (MB) | WER | CER | WER-LM | CER-LM | Language | |
|---|---|---|---|---|---|---|---|
| tiny-conformer | 24.4 | 9.14 | 0.212811 | 0.081369 | 0.199683 | 0.077004 | [malay] |
| small-conformer | 49.2 | 18.1 | 0.198533 | 0.074495 | 0.185361 | 0.071143 | [malay] |
| conformer | 125 | 37.1 | 0.163602 | 0.058744 | 0.156182 | 0.05719 | [malay] |
| large-conformer | 404 | 107 | 0.156684 | 0.061971 | 0.148622 | 0.05901 | [malay] |
| conformer-stack-2mixed | 130 | 38.5 | 0.103608 | 0.050069 | 0.102911 | 0.050201 | [malay, singlish] |
| conformer-stack-3mixed | 130 | 38.5 | 0.234768 | 0.133944 | 0.229241 | 0.130702 | [malay, singlish, mandarin] |
| small-conformer-singlish | 49.2 | 18.1 | 0.087831 | 0.045686 | 0.087333 | 0.045317 | [singlish] |
| conformer-singlish | 125 | 37.1 | 0.077792 | 0.040362 | 0.077186 | 0.03987 | [singlish] |
| large-conformer-singlish | 404 | 107 | 0.070147 | 0.035872 | 0.069812 | 0.035723 | [singlish] |
Lower is better. Mixed models tested on different dataset.
Load RNNT model#
def deep_transducer(
model: str = 'conformer', quantized: bool = False, **kwargs
):
"""
Load Encoder-Transducer ASR model.
Parameters
----------
model : str, optional (default='conformer')
Model architecture supported. Allowed values:
* ``'tiny-conformer'`` - TINY size Google Conformer.
* ``'small-conformer'`` - SMALL size Google Conformer.
* ``'conformer'`` - BASE size Google Conformer.
* ``'large-conformer'`` - LARGE size Google Conformer.
* ``'conformer-stack-2mixed'`` - BASE size Stacked Google Conformer for (Malay + Singlish) languages.
* ``'conformer-stack-3mixed'`` - BASE size Stacked Google Conformer for (Malay + Singlish + Mandarin) languages.
* ``'small-conformer-singlish'`` - SMALL size Google Conformer for singlish language.
* ``'conformer-singlish'`` - BASE size Google Conformer for singlish language.
* ``'large-conformer-singlish'`` - LARGE size Google Conformer for singlish language.
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
Returns
-------
result : malaya_speech.model.tf.Transducer class
"""
[4]:
model = malaya_speech.stt.deep_transducer(model = 'conformer')
web inference using Gradio#
def gradio(self, record_mode: bool = True, **kwargs):
"""
Transcribe an input using beam decoder on Gradio interface.
Parameters
----------
record_mode: bool, optional (default=True)
if True, Gradio will use record mode, else, file upload mode.
**kwargs: keyword arguments for beam decoder and `iface.launch`.
"""
record mode#
[6]:
model.gradio(record_mode = True)
[10]:
from IPython.core.display import Image, display
display(Image('record-mode.png', width=800))
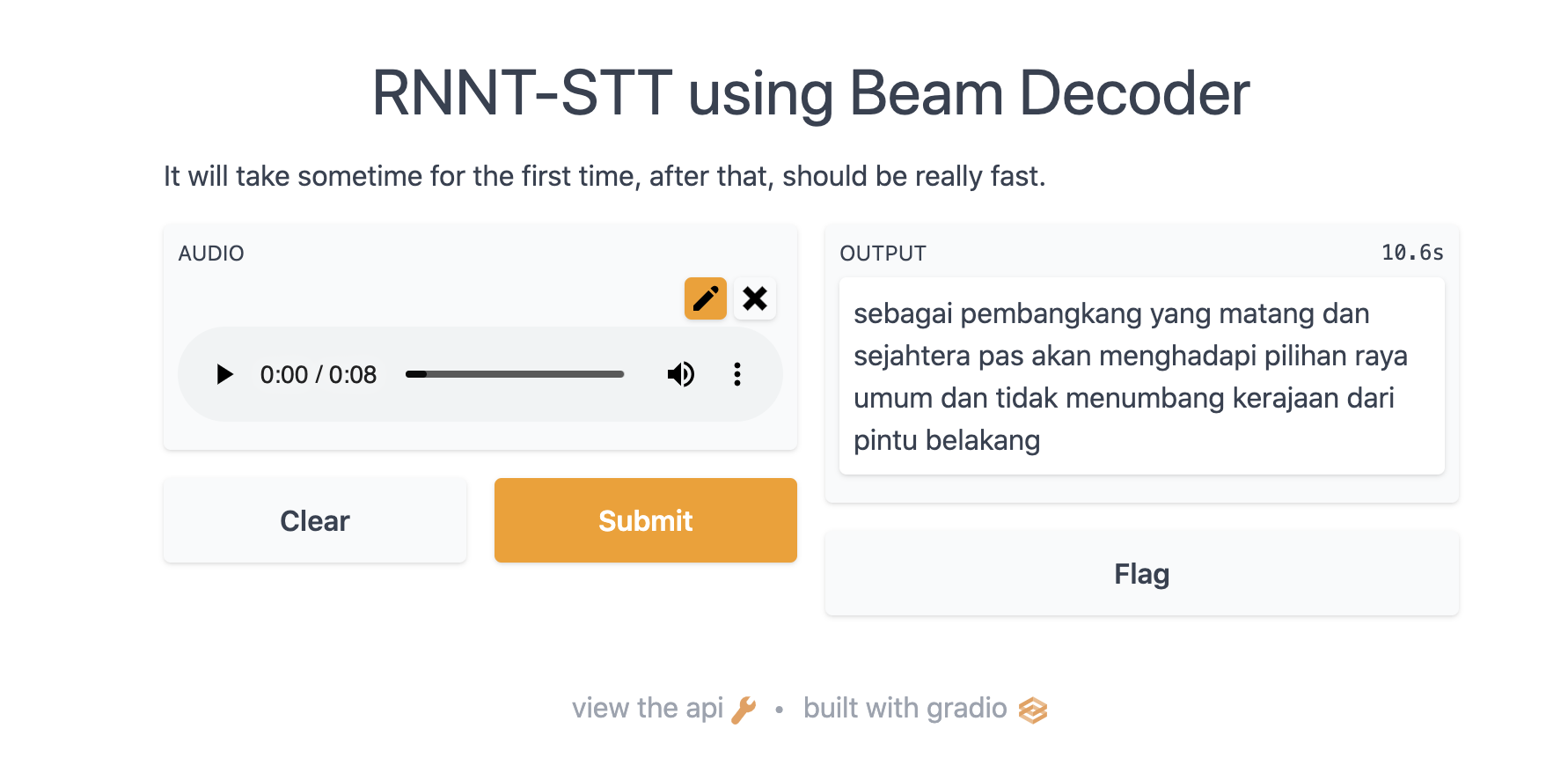
upload mode#
[9]:
model.gradio(record_mode = False)
[11]:
from IPython.core.display import Image, display
display(Image('upload-mode.png', width=800))
[ ]: