
Speaker Vector
Contents
Speaker Vector#
This tutorial is available as an IPython notebook at malaya-speech/example/speaker-vector.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
[1]:
from malaya_speech import Pipeline
import malaya_speech
import numpy as np
List available deep model#
[2]:
malaya_speech.speaker_vector.available_model()
INFO:root:tested on VoxCeleb2 test set. Lower EER is better.
[2]:
| Size (MB) | Quantized Size (MB) | Embedding Size | EER | |
|---|---|---|---|---|
| deep-speaker | 96.7 | 24.40 | 512.0 | 0.21870 |
| vggvox-v1 | 70.8 | 17.70 | 1024.0 | 0.14070 |
| vggvox-v2 | 43.2 | 7.92 | 512.0 | 0.04450 |
| speakernet | 35.0 | 8.88 | 7205.0 | 0.02122 |
Smaller EER the better model is.
Load deep model#
def deep_model(model: str = 'speakernet', quantized: bool = False, **kwargs):
"""
Load Speaker2Vec model.
Parameters
----------
model : str, optional (default='speakernet')
Model architecture supported. Allowed values:
* ``'vggvox-v1'`` - VGGVox V1, embedding size 1024
* ``'vggvox-v2'`` - VGGVox V2, embedding size 512
* ``'deep-speaker'`` - Deep Speaker, embedding size 512
* ``'speakernet'`` - SpeakerNet, embedding size 7205
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
Returns
-------
result : malaya_speech.supervised.classification.load function
"""
[3]:
model = malaya_speech.speaker_vector.deep_model('speakernet')
Load Quantized deep model#
To load 8-bit quantized model, simply pass quantized = True, default is False.
We can expect slightly accuracy drop from quantized model, and not necessary faster than normal 32-bit float model, totally depends on machine.
[4]:
quantized_model = malaya_speech.speaker_vector.deep_model('speakernet', quantized = True)
WARNING:root:Load quantized model will cause accuracy drop.
/Users/huseinzolkepli/Documents/tf-1.15/env/lib/python3.7/site-packages/tensorflow_core/python/client/session.py:1750: UserWarning: An interactive session is already active. This can cause out-of-memory errors in some cases. You must explicitly call `InteractiveSession.close()` to release resources held by the other session(s).
warnings.warn('An interactive session is already active. This can '
[5]:
from glob import glob
speakers = ['speech/example-speaker/khalil-nooh.wav',
'speech/example-speaker/mas-aisyah.wav',
'speech/example-speaker/shafiqah-idayu.wav',
'speech/example-speaker/husein-zolkepli.wav']
Pipeline#
[6]:
def load_wav(file):
return malaya_speech.load(file)[0]
p = Pipeline()
frame = p.foreach_map(load_wav).map(model)
[7]:
p.visualize()
[7]:
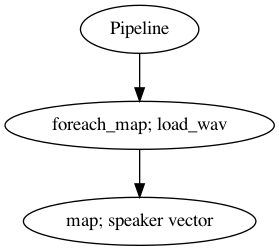
[8]:
r = p.emit(speakers)
[9]:
quantized_p = Pipeline()
quantized_frame = quantized_p.foreach_map(load_wav).map(quantized_model)
[10]:
quantized_r = quantized_p.emit(speakers)
Calculate similarity#
[11]:
from scipy.spatial.distance import cdist
1 - cdist(r['speaker-vector'], r['speaker-vector'], metric = 'cosine')
[11]:
array([[1. , 0.85895569, 0.85036787, 0.919863 ],
[0.85895569, 1. , 0.88895719, 0.85086463],
[0.85036787, 0.88895719, 1. , 0.86070389],
[0.919863 , 0.85086463, 0.86070389, 1. ]])
[12]:
from scipy.spatial.distance import cdist
1 - cdist(quantized_r['speaker-vector'], quantized_r['speaker-vector'], metric = 'cosine')
[12]:
array([[1. , 0.86325292, 0.8574443 , 0.92556189],
[0.86325292, 1. , 0.88897938, 0.85685812],
[0.8574443 , 0.88897938, 1. , 0.86453416],
[0.92556189, 0.85685812, 0.86453416, 1. ]])
Remember, our files are,
['speech/example-speaker/khalil-nooh.wav',
'speech/example-speaker/mas-aisyah.wav',
'speech/example-speaker/shafiqah-idayu.wav',
'speech/example-speaker/husein-zolkepli.wav']
If we check first row,
[1. , 0.86325292, 0.8574443 , 0.92556189]
second biggest is 0.91986299, which is 4th column, for husein-zolkepli.wav. So the speaker vector knows khalil-nooh.wav sounds similar to husein-zolkepli.wav due to gender factor.
Reference#
deep-speaker, https://github.com/philipperemy/deep-speaker, exported from Keras to TF checkpoint.
vggvox-v1, https://github.com/linhdvu14/vggvox-speaker-identification, exported from Keras to TF checkpoint.
vggvox-v2, https://github.com/WeidiXie/VGG-Speaker-Recognition, exported from Keras to TF checkpoint.
speakernet, Nvidia NeMo, https://github.com/NVIDIA/NeMo/tree/main/examples/speaker_recognition, exported from Pytorch to TF.
VoxCeleb2, speaker verification dataset, http://www.robots.ox.ac.uk/~vgg/data/voxceleb/index.html#about