
Force Alignment using CTC HuggingFace
Contents
Force Alignment using CTC HuggingFace#
Finetuned hyperlocal languages on pretrained HuggingFace models, https://huggingface.co/mesolitica
This tutorial is available as an IPython notebook at malaya-speech/example/force-alignment-ctc-huggingface.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
import IPython.display as ipd
import matplotlib.pyplot as plt
from malaya_speech.utils.aligner import plot_alignments
`pyaudio` is not available, `malaya_speech.streaming.pyaudio` is not able to use.
List available HuggingFace model#
[2]:
malaya_speech.force_alignment.ctc.available_huggingface()
[2]:
| Size (MB) | malay-malaya | malay-fleur102 | singlish | Language | |
|---|---|---|---|---|---|
| mesolitica/wav2vec2-xls-r-300m-mixed | 1180 | {'WER': 0.194655128, 'CER': 0.04775798, 'WER-L... | {'WER': 0.2373861259, 'CER': 0.07055478, 'WER-... | {'WER': 0.127588595, 'CER': 0.0494924979, 'WER... | [malay, singlish] |
| mesolitica/wav2vec2-xls-r-300m-mixed-v2 | 1180 | {'WER': 0.154782923, 'CER': 0.035164031, 'WER-... | {'WER': 0.2013994374, 'CER': 0.0518170369, 'WE... | {'WER': 0.2258822139, 'CER': 0.082982312, 'WER... | [malay, singlish] |
| mesolitica/wav2vec2-xls-r-300m-12layers-ms | 657 | {'WER': 0.1494983789, 'CER': 0.0342059992, 'WE... | {'WER': 0.217107489, 'CER': 0.0546614199, 'WER... | NaN | [malay] |
| mesolitica/wav2vec2-xls-r-300m-6layers-ms | 339 | {'WER': 0.22481538553, 'CER': 0.0484392694, 'W... | {'WER': 0.38642364985, 'CER': 0.0928960677, 'W... | NaN | [malay] |
Load HuggingFace model#
def huggingface(
model: str = 'mesolitica/wav2vec2-xls-r-300m-mixed',
force_check: bool = True,
**kwargs
):
"""
Load Finetuned models from HuggingFace.
Parameters
----------
model : str, optional (default='mesolitica/wav2vec2-xls-r-300m-mixed')
Check available models at `malaya_speech.force_alignment.ctc.available_huggingface()`.
force_check: bool, optional (default=True)
Force check model one of malaya model.
Set to False if you have your own huggingface model.
Returns
-------
result : malaya_speech.model.huggingface.Aligner class
"""
[7]:
model = malaya_speech.force_alignment.ctc.huggingface(model = 'mesolitica/wav2vec2-xls-r-300m-mixed')
Load sample#
Malay samples#
[8]:
malay1, sr = malaya_speech.load('speech/example-speaker/shafiqah-idayu.wav')
malay2, sr = malaya_speech.load('speech/example-speaker/haqkiem.wav')
[9]:
texts = ['nama saya shafiqah idayu',
'sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang']
[10]:
ipd.Audio(malay2, rate = sr)
[10]:
Singlish samples#
[11]:
import json
import os
from glob import glob
with open('speech/imda/output.json') as fopen:
data = json.load(fopen)
data
[11]:
{'221931702.WAV': 'wantan mee is a traditional local cuisine',
'221931818.WAV': 'ahmad khan adelene wee chin suan and robert ibbetson',
'221931727.WAV': 'saravanan gopinathan george yeo yong boon and tay kheng soon'}
[12]:
wavs = glob('speech/imda/*.WAV')
wavs
[12]:
['speech/imda/221931727.WAV',
'speech/imda/221931818.WAV',
'speech/imda/221931702.WAV']
[13]:
y, sr = malaya_speech.load(wavs[0])
[14]:
ipd.Audio(y, rate = sr)
[14]:
Predict#
def predict(self, input, transcription: str, sample_rate: int = 16000):
"""
Transcribe input, will return a string.
Parameters
----------
input: np.array
np.array or malaya_speech.model.frame.Frame.
transcription: str
transcription of input audio.
sample_rate: int, optional (default=16000)
sample rate for `input`.
Returns
-------
result: Dict[chars_alignment, words_alignment, alignment]
"""
Predict Malay#
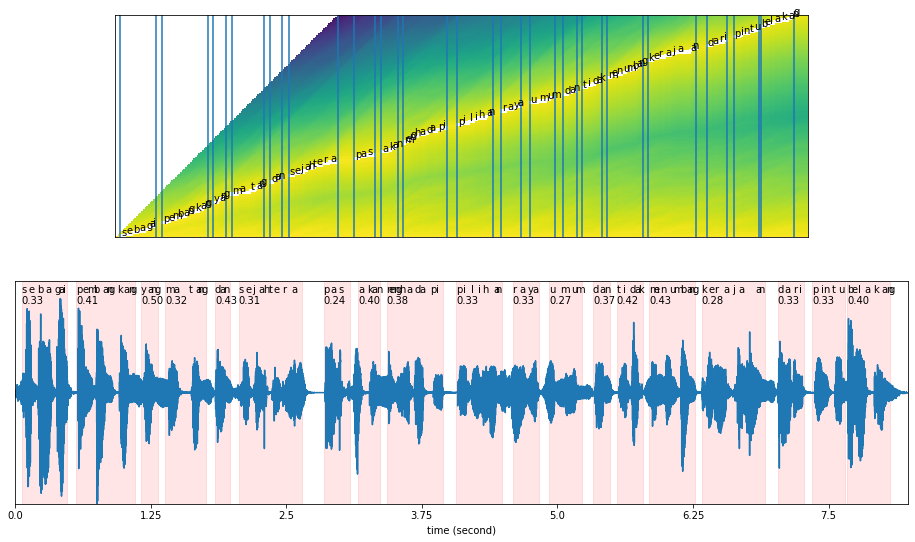
Our original text is: ‘sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang’
[15]:
results = model.predict(malay2, texts[1])
[16]:
results.keys()
[16]:
dict_keys(['chars_alignment', 'words_alignment', 'alignment'])
[17]:
results['words_alignment']
[17]:
[{'text': 'sebagai',
'start': 0.06008348540145986,
'end': 0.48066788321167886,
'start_t': 3,
'end_t': 24,
'score': 0.33321882429577904},
{'text': 'pembangkang',
'start': 0.560779197080292,
'end': 1.1015305656934307,
'start_t': 28,
'end_t': 55,
'score': 0.4062712302914377},
{'text': 'yang',
'start': 1.1616140510948907,
'end': 1.321836678832117,
'start_t': 58,
'end_t': 66,
'score': 0.4999573007225997},
{'text': 'matang',
'start': 1.3819201642335768,
'end': 1.7624489051094892,
'start_t': 69,
'end_t': 88,
'score': 0.3155402164710425},
{'text': 'dan',
'start': 1.8425602189781023,
'end': 1.9827550182481752,
'start_t': 92,
'end_t': 99,
'score': 0.4285128627504628},
{'text': 'sejahtera',
'start': 2.0628663321167884,
'end': 2.643673357664234,
'start_t': 103,
'end_t': 132,
'score': 0.3079770104638471},
{'text': 'pas',
'start': 2.8439516423357665,
'end': 3.084285583941606,
'start_t': 142,
'end_t': 154,
'score': 0.2448273152115185},
{'text': 'akan',
'start': 3.164396897810219,
'end': 3.364675182481752,
'start_t': 158,
'end_t': 168,
'score': 0.3999038577079774},
{'text': 'menghadapi',
'start': 3.424758667883212,
'end': 3.945482208029197,
'start_t': 171,
'end_t': 197,
'score': 0.38456097932962396},
{'text': 'pilihan',
'start': 4.065649178832117,
'end': 4.486233576642336,
'start_t': 203,
'end_t': 224,
'score': 0.3332554669607255},
{'text': 'raya',
'start': 4.586372718978103,
'end': 4.826706660583942,
'start_t': 229,
'end_t': 241,
'score': 0.3331461350123278},
{'text': 'umum',
'start': 4.926845802919709,
'end': 5.227263229927008,
'start_t': 246,
'end_t': 261,
'score': 0.26627070903778116},
{'text': 'dan',
'start': 5.327402372262774,
'end': 5.487625,
'start_t': 266,
'end_t': 274,
'score': 0.37489531934261544},
{'text': 'tidak',
'start': 5.54770848540146,
'end': 5.7880424270073,
'start_t': 277,
'end_t': 289,
'score': 0.4166095902522405},
{'text': 'menumbang',
'start': 5.84812591240876,
'end': 6.268710310218978,
'start_t': 292,
'end_t': 313,
'score': 0.42670088154929364},
{'text': 'kerajaan',
'start': 6.328793795620438,
'end': 6.909600821167883,
'start_t': 316,
'end_t': 345,
'score': 0.275826780960479},
{'text': 'dari',
'start': 7.029767791970803,
'end': 7.2701017335766425,
'start_t': 351,
'end_t': 363,
'score': 0.3333086719115578},
{'text': 'pintu',
'start': 7.350213047445256,
'end': 7.650630474452555,
'start_t': 367,
'end_t': 382,
'score': 0.33326695760091263},
{'text': 'belakang',
'start': 7.670658302919708,
'end': 8.071214872262773,
'start_t': 383,
'end_t': 403,
'score': 0.3998415201902393}]
Plot alignment#
def plot_alignments(
alignment,
subs_alignment,
words_alignment,
waveform,
separator: str = ' ',
sample_rate: int = 16000,
figsize: tuple = (16, 9),
plot_score_char: bool = False,
plot_score_word: bool = True,
):
"""
plot alignment.
Parameters
----------
alignment: np.array
usually `alignment` output.
subs_alignment: list
usually `chars_alignment` or `subwords_alignment` output.
words_alignment: list
usually `words_alignment` output.
waveform: np.array
input audio.
separator: str, optional (default=' ')
separator between words, only useful if `subs_alignment` is character based.
sample_rate: int, optional (default=16000)
figsize: tuple, optional (default=(16, 9))
figure size for matplotlib `figsize`.
plot_score_char: bool, optional (default=False)
plot score on top of character plots.
plot_score_word: bool, optional (default=True)
plot score on top of word plots.
"""
[18]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = malay2,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
Predict Singlish#
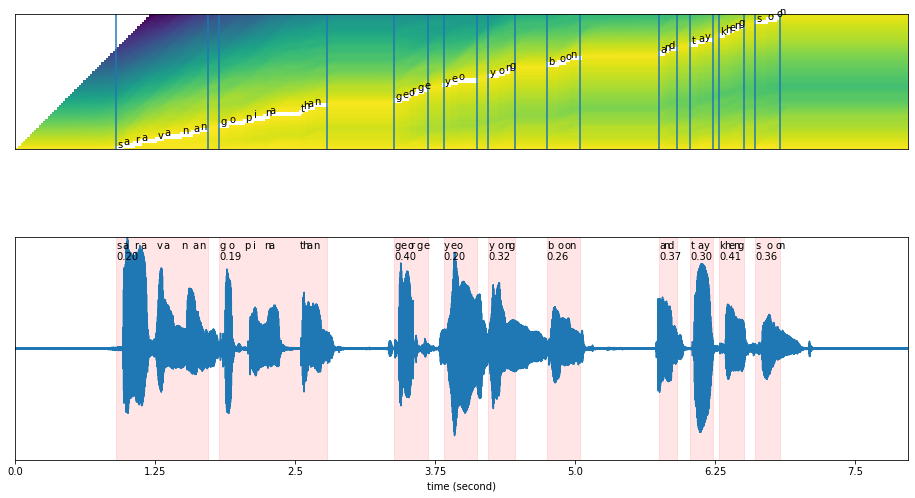
Our original text is: ‘saravanan gopinathan george yeo yong boon and tay kheng soon’
[19]:
results = model.predict(y, data[os.path.split(wavs[0])[1]])
[20]:
results.keys()
[20]:
dict_keys(['chars_alignment', 'words_alignment', 'alignment'])
[21]:
results['words_alignment']
[21]:
[{'text': 'saravanan',
'start': 0.9011306532663317,
'end': 1.7221608040201006,
'start_t': 45,
'end_t': 86,
'score': 0.20384642409138573},
{'text': 'gopinathan',
'start': 1.822286432160804,
'end': 2.783492462311558,
'start_t': 91,
'end_t': 139,
'score': 0.18884460441868942},
{'text': 'george',
'start': 3.384246231155779,
'end': 3.6846231155778897,
'start_t': 169,
'end_t': 184,
'score': 0.39843229452776235},
{'text': 'yeo',
'start': 3.8247989949748744,
'end': 4.125175879396985,
'start_t': 191,
'end_t': 206,
'score': 0.19766118923832002},
{'text': 'yong',
'start': 4.225301507537688,
'end': 4.465603015075377,
'start_t': 211,
'end_t': 223,
'score': 0.31750804185869463},
{'text': 'boon',
'start': 4.745954773869347,
'end': 5.046331658291457,
'start_t': 237,
'end_t': 252,
'score': 0.2619178016980702},
{'text': 'and',
'start': 5.747211055276382,
'end': 5.907412060301508,
'start_t': 287,
'end_t': 295,
'score': 0.37494328618058853},
{'text': 'tay',
'start': 6.027562814070352,
'end': 6.227814070351759,
'start_t': 301,
'end_t': 311,
'score': 0.29917768239975223},
{'text': 'kheng',
'start': 6.287889447236181,
'end': 6.508165829145729,
'start_t': 314,
'end_t': 325,
'score': 0.4098080234094169},
{'text': 'soon',
'start': 6.608291457286432,
'end': 6.82856783919598,
'start_t': 330,
'end_t': 341,
'score': 0.3609583919698551}]
[22]:
results['chars_alignment']
[22]:
[{'text': 's',
'start': 0.9011306532663317,
'end': 0.9612060301507538,
'start_t': 45,
'end_t': 48,
'score': 0.3240376313529698},
{'text': 'a',
'start': 0.9612060301507538,
'end': 1.0613316582914574,
'start_t': 48,
'end_t': 53,
'score': 0.16172151565578854},
{'text': 'r',
'start': 1.0613316582914574,
'end': 1.1214070351758794,
'start_t': 53,
'end_t': 56,
'score': 0.32714581489564043},
{'text': 'a',
'start': 1.1214070351758794,
'end': 1.2615829145728643,
'start_t': 56,
'end_t': 63,
'score': 0.13863981621621668},
{'text': 'v',
'start': 1.2615829145728643,
'end': 1.3216582914572865,
'start_t': 63,
'end_t': 66,
'score': 0.3100898265839032},
{'text': 'a',
'start': 1.3216582914572865,
'end': 1.481859296482412,
'start_t': 66,
'end_t': 74,
'score': 0.12218087911618031},
{'text': 'n',
'start': 1.481859296482412,
'end': 1.5819849246231157,
'start_t': 74,
'end_t': 79,
'score': 0.19260255098444917},
{'text': 'a',
'start': 1.5819849246231157,
'end': 1.6420603015075377,
'start_t': 79,
'end_t': 82,
'score': 0.3277939558029208},
{'text': 'n',
'start': 1.6420603015075377,
'end': 1.7221608040201006,
'start_t': 82,
'end_t': 86,
'score': 0.19273890554909107},
{'text': ' ',
'start': 1.7221608040201006,
'end': 1.822286432160804,
'start_t': 86,
'end_t': 91,
'score': 0.19821752309799198},
{'text': 'g',
'start': 1.822286432160804,
'end': 1.9023869346733668,
'start_t': 91,
'end_t': 95,
'score': 0.24466364085675005},
{'text': 'o',
'start': 1.9023869346733668,
'end': 2.042562814070352,
'start_t': 95,
'end_t': 102,
'score': 0.14236060210639628},
{'text': 'p',
'start': 2.042562814070352,
'end': 2.1226633165829147,
'start_t': 102,
'end_t': 106,
'score': 0.24587956070903033},
{'text': 'i',
'start': 2.1226633165829147,
'end': 2.222788944723618,
'start_t': 106,
'end_t': 111,
'score': 0.194324076175767},
{'text': 'n',
'start': 2.222788944723618,
'end': 2.2628391959798995,
'start_t': 111,
'end_t': 113,
'score': 0.48097959160833914},
{'text': 'a',
'start': 2.2628391959798995,
'end': 2.5431909547738694,
'start_t': 113,
'end_t': 127,
'score': 0.06657216804703243},
{'text': 't',
'start': 2.5431909547738694,
'end': 2.56321608040201,
'start_t': 127,
'end_t': 128,
'score': 0.9809843897819519},
{'text': 'h',
'start': 2.56321608040201,
'end': 2.6032663316582916,
'start_t': 128,
'end_t': 130,
'score': 0.14145611226561222},
{'text': 'a',
'start': 2.6032663316582916,
'end': 2.663341708542714,
'start_t': 130,
'end_t': 133,
'score': 0.33082079887391125},
{'text': 'n',
'start': 2.663341708542714,
'end': 2.783492462311558,
'start_t': 133,
'end_t': 139,
'score': 0.16398251056671975},
{'text': ' ',
'start': 2.783492462311558,
'end': 3.384246231155779,
'start_t': 139,
'end_t': 169,
'score': 0.03276375532150275},
{'text': 'g',
'start': 3.384246231155779,
'end': 3.4443216080402013,
'start_t': 169,
'end_t': 172,
'score': 0.33324092626607155},
{'text': 'e',
'start': 3.4443216080402013,
'end': 3.504396984924623,
'start_t': 172,
'end_t': 175,
'score': 0.33212047815323603},
{'text': 'o',
'start': 3.504396984924623,
'end': 3.5244221105527638,
'start_t': 175,
'end_t': 176,
'score': 0.9839329719543457},
{'text': 'r',
'start': 3.5244221105527638,
'end': 3.584497487437186,
'start_t': 176,
'end_t': 179,
'score': 0.3329786459604899},
{'text': 'g',
'start': 3.584497487437186,
'end': 3.644572864321608,
'start_t': 179,
'end_t': 182,
'score': 0.3331602414449056},
{'text': 'e',
'start': 3.644572864321608,
'end': 3.6846231155778897,
'start_t': 182,
'end_t': 184,
'score': 0.49902528524399004},
{'text': ' ',
'start': 3.6846231155778897,
'end': 3.8247989949748744,
'start_t': 184,
'end_t': 191,
'score': 0.14271241426467904},
{'text': 'y',
'start': 3.8247989949748744,
'end': 3.8848743718592966,
'start_t': 191,
'end_t': 194,
'score': 0.32723299662272143},
{'text': 'e',
'start': 3.8848743718592966,
'end': 3.944949748743719,
'start_t': 194,
'end_t': 197,
'score': 0.3290887872378048},
{'text': 'o',
'start': 3.944949748743719,
'end': 4.125175879396985,
'start_t': 197,
'end_t': 206,
'score': 0.11066138744369124},
{'text': ' ',
'start': 4.125175879396985,
'end': 4.225301507537688,
'start_t': 206,
'end_t': 211,
'score': 0.19952495098114054},
{'text': 'y',
'start': 4.225301507537688,
'end': 4.305402010050251,
'start_t': 211,
'end_t': 215,
'score': 0.248589888215072},
{'text': 'o',
'start': 4.305402010050251,
'end': 4.365477386934673,
'start_t': 215,
'end_t': 218,
'score': 0.3313915729523465},
{'text': 'n',
'start': 4.365477386934673,
'end': 4.4055276381909545,
'start_t': 218,
'end_t': 220,
'score': 0.4653806388378151},
{'text': 'g',
'start': 4.4055276381909545,
'end': 4.465603015075377,
'start_t': 220,
'end_t': 223,
'score': 0.29693365097045926},
{'text': ' ',
'start': 4.465603015075377,
'end': 4.745954773869347,
'start_t': 223,
'end_t': 237,
'score': 0.07138291852814811},
{'text': 'b',
'start': 4.745954773869347,
'end': 4.846080402010051,
'start_t': 237,
'end_t': 242,
'score': 0.19986052513122565},
{'text': 'o',
'start': 4.846080402010051,
'end': 4.9061557788944725,
'start_t': 242,
'end_t': 245,
'score': 0.33312906821568805},
{'text': 'o',
'start': 4.9061557788944725,
'end': 4.946206030150754,
'start_t': 245,
'end_t': 247,
'score': 0.4656797647477771},
{'text': 'n',
'start': 4.946206030150754,
'end': 5.046331658291457,
'start_t': 247,
'end_t': 252,
'score': 0.19974353313446125},
{'text': ' ',
'start': 5.046331658291457,
'end': 5.747211055276382,
'start_t': 252,
'end_t': 287,
'score': 0.028549667767116003},
{'text': 'a',
'start': 5.747211055276382,
'end': 5.787261306532663,
'start_t': 287,
'end_t': 289,
'score': 0.4999660551551689},
{'text': 'n',
'start': 5.787261306532663,
'end': 5.827311557788945,
'start_t': 289,
'end_t': 291,
'score': 0.4998745322227478},
{'text': 'd',
'start': 5.827311557788945,
'end': 5.907412060301508,
'start_t': 291,
'end_t': 295,
'score': 0.24996627867221868},
{'text': ' ',
'start': 5.907412060301508,
'end': 6.027562814070352,
'start_t': 295,
'end_t': 301,
'score': 0.16642684737841287},
{'text': 't',
'start': 6.027562814070352,
'end': 6.087638190954774,
'start_t': 301,
'end_t': 304,
'score': 0.33315388361613124},
{'text': 'a',
'start': 6.087638190954774,
'end': 6.1477135678391965,
'start_t': 304,
'end_t': 307,
'score': 0.3327598174413108},
{'text': 'y',
'start': 6.1477135678391965,
'end': 6.227814070351759,
'start_t': 307,
'end_t': 311,
'score': 0.2485089302062991},
{'text': ' ',
'start': 6.227814070351759,
'end': 6.287889447236181,
'start_t': 311,
'end_t': 314,
'score': 0.33261001110077903},
{'text': 'k',
'start': 6.287889447236181,
'end': 6.327939698492463,
'start_t': 314,
'end_t': 316,
'score': 0.49705055356027067},
{'text': 'h',
'start': 6.327939698492463,
'end': 6.367989949748744,
'start_t': 316,
'end_t': 318,
'score': 0.2730940580368096},
{'text': 'e',
'start': 6.367989949748744,
'end': 6.408040201005026,
'start_t': 318,
'end_t': 320,
'score': 0.4960979819297957},
{'text': 'n',
'start': 6.408040201005026,
'end': 6.448090452261306,
'start_t': 320,
'end_t': 322,
'score': 0.49269518256187445},
{'text': 'g',
'start': 6.448090452261306,
'end': 6.508165829145729,
'start_t': 322,
'end_t': 325,
'score': 0.3300042351086952},
{'text': ' ',
'start': 6.508165829145729,
'end': 6.608291457286432,
'start_t': 325,
'end_t': 330,
'score': 0.1999395012855531},
{'text': 's',
'start': 6.608291457286432,
'end': 6.708417085427135,
'start_t': 330,
'end_t': 335,
'score': 0.19994559288025032},
{'text': 'o',
'start': 6.708417085427135,
'end': 6.788517587939698,
'start_t': 335,
'end_t': 339,
'score': 0.24943961203098375},
{'text': 'o',
'start': 6.788517587939698,
'end': 6.80854271356784,
'start_t': 339,
'end_t': 340,
'score': 0.981655478477478},
{'text': 'n',
'start': 6.80854271356784,
'end': 6.82856783919598,
'start_t': 340,
'end_t': 341,
'score': 0.991400420665741}]
[23]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = y,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
What if we give wrong transcription?#
[24]:
results = model.predict(y, 'husein sangat comel')
[25]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['chars_alignment'],
words_alignment = results['words_alignment'],
waveform = y,
separator = ' ',
sample_rate = 16000,
figsize = (16, 9))
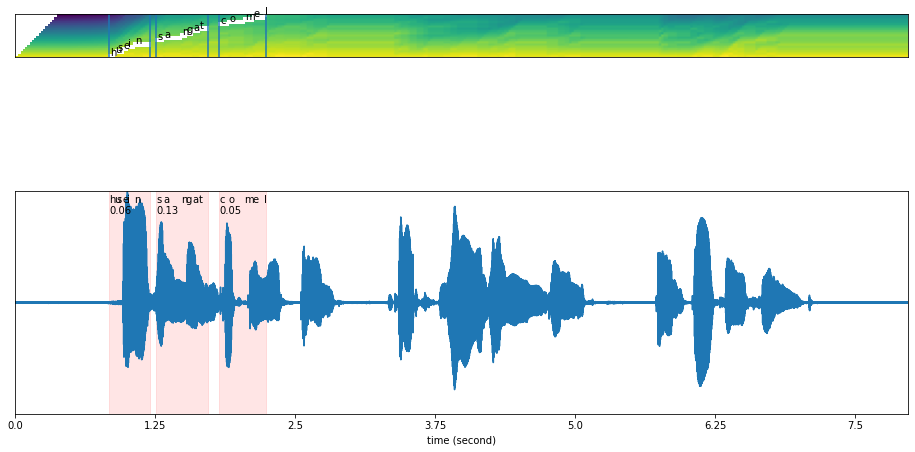
The text output not able to align, and returned scores very low.