
Speaker Diarization using Features
Contents
Speaker Diarization using Features#
This tutorial is available as an IPython notebook at malaya-speech/example/diarization-features.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
What is the different with Speaker Diarization#
Current speaker diarization, https://malaya-speech.readthedocs.io/en/latest/load-diarization.html
Required a pipeline, VAD -> Group positive VADs -> Speaker models -> Clustering, and this pipeline required a really good VAD and Speaker models. What if we can directly cluster using STFT / Features and arange the timestamp.
Inspired by khursani8,
Wave -> STFT / Features -> Clustering -> arange timestamp.
The features can be anything, such as,
MFCC
Melspectrogram
Conv
[1]:
from malaya_speech import Pipeline
import malaya_speech
import numpy as np
import matplotlib.pyplot as plt
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/tensorflow_addons/utils/ensure_tf_install.py:67: UserWarning: Tensorflow Addons supports using Python ops for all Tensorflow versions above or equal to 2.3.0 and strictly below 2.5.0 (nightly versions are not supported).
The versions of TensorFlow you are currently using is 2.5.0 and is not supported.
Some things might work, some things might not.
If you were to encounter a bug, do not file an issue.
If you want to make sure you're using a tested and supported configuration, either change the TensorFlow version or the TensorFlow Addons's version.
You can find the compatibility matrix in TensorFlow Addon's readme:
https://github.com/tensorflow/addons
UserWarning,
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/tensorflow_addons/utils/resource_loader.py:103: UserWarning: You are currently using TensorFlow 2.5.0 and trying to load a custom op (custom_ops/seq2seq/_beam_search_ops.so).
TensorFlow Addons has compiled its custom ops against TensorFlow 2.4.0, and there are no compatibility guarantees between the two versions.
This means that you might get segfaults when loading the custom op, or other kind of low-level errors.
If you do, do not file an issue on Github. This is a known limitation.
It might help you to fallback to pure Python ops with TF_ADDONS_PY_OPS . To do that, see https://github.com/tensorflow/addons#gpucpu-custom-ops
You can also change the TensorFlow version installed on your system. You would need a TensorFlow version equal to or above 2.4.0 and strictly below 2.5.0.
Note that nightly versions of TensorFlow, as well as non-pip TensorFlow like `conda install tensorflow` or compiled from source are not supported.
The last solution is to find the TensorFlow Addons version that has custom ops compatible with the TensorFlow installed on your system. To do that, refer to the readme: https://github.com/tensorflow/addons
UserWarning,
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/malaya_boilerplate-0.0.10-py3.7.egg/malaya_boilerplate/frozen_graph.py:28: UserWarning: Cannot import beam_search_ops from Tensorflow Addons, `deep_model` for stemmer will not available to use, make sure Tensorflow Addons version >= 0.12.0
Load audio sample#
[2]:
y, sr = malaya_speech.load('speech/video/The-Singaporean-White-Boy.wav')
len(y), sr
[2]:
(1634237, 16000)
[3]:
# just going to take 60 seconds
y = y[:sr * 60]
This audio extracted from https://www.youtube.com/watch?v=HylaY5e1awo&t=2s
Generate Log Melspectrogram#
You can use interface malaya_speech.utils.featurization.STTFeaturizer,
class STTFeaturizer:
def __init__(
self,
sample_rate=16000,
frame_ms=25,
stride_ms=10,
nfft=None,
num_feature_bins=80,
feature_type='log_mel_spectrogram',
preemphasis=0.97,
dither=1e-5,
normalize_signal=True,
normalize_feature=True,
norm_per_feature=True,
**kwargs,
):
"""
sample_rate: int, optional (default=16000)
frame_ms: int, optional (default=25)
To calculate `frame_length` for librosa STFT, `frame_length = int(sample_rate * (frame_ms / 1000))`
stride_ms: int, optional (default=10)
To calculate `frame_step` for librosa STFT, `frame_step = int(sample_rate * (stride_ms / 1000))`
nfft: int, optional (default=None)
If None, will calculate by `math.ceil(math.log2((frame_ms / 1000) * sample_rate))`
num_feature_bins: int, optional (default=80)
Size of output features.
feature_type: str, optional (default='log_mel_spectrogram')
Features type, allowed values:
* ``'spectrogram'`` - np.square(np.abs(librosa.core.stft))
* ``'mfcc'`` - librosa.feature.mfcc(np.square(np.abs(librosa.core.stft)))
* ``'log_mel_spectrogram'`` - log(mel(np.square(np.abs(librosa.core.stft))))
"""
Spectral Clustering#
This is a Python re-implementation of the spectral clustering algorithm in the paper Speaker Diarization with LSTM.
So, make sure you already install spectralcluster,
pip install spectralcluster
[38]:
from spectralcluster import SpectralClusterer
clusterer = SpectralClusterer(
min_clusters=1,
max_clusters=100,
p_percentile=0.95,
gaussian_blur_sigma=30.0,
)
Clustering on log MelSpectrogram#
[43]:
%%time
featurizer = malaya_speech.featurization.STTFeaturizer(feature_type = 'log_mel_spectrogram',
frame_ms = 50, stride_ms = 30)
features = featurizer(y)
features.shape
CPU times: user 110 ms, sys: 31.2 ms, total: 141 ms
Wall time: 111 ms
[43]:
(2001, 80)
[44]:
from malaya_speech.utils.dist import l2_normalize
[45]:
%%time
cluster_labels = clusterer.predict(l2_normalize(features))
frames = malaya_speech.arange.arange_frames(features, y, sr)
results = []
for no, result in enumerate(cluster_labels):
results.append((frames[no], result))
grouped = malaya_speech.group.group_frames(results)
CPU times: user 15.3 s, sys: 1.56 s, total: 16.8 s
Wall time: 5.2 s
[46]:
grouped
[46]:
[(<malaya_speech.model.frame.Frame at 0x16b7e5250>, 1),
(<malaya_speech.model.frame.Frame at 0x17b77d790>, 2),
(<malaya_speech.model.frame.Frame at 0x17b77db10>, 1),
(<malaya_speech.model.frame.Frame at 0x17b77d090>, 2),
(<malaya_speech.model.frame.Frame at 0x17b77da50>, 1),
(<malaya_speech.model.frame.Frame at 0x17b77d650>, 2),
(<malaya_speech.model.frame.Frame at 0x16cece210>, 0),
(<malaya_speech.model.frame.Frame at 0x16ceced90>, 1),
(<malaya_speech.model.frame.Frame at 0x16cece450>, 0),
(<malaya_speech.model.frame.Frame at 0x17b77de90>, 1),
(<malaya_speech.model.frame.Frame at 0x16cece150>, 0),
(<malaya_speech.model.frame.Frame at 0x16cece950>, 2),
(<malaya_speech.model.frame.Frame at 0x16cecea90>, 0),
(<malaya_speech.model.frame.Frame at 0x1856b8210>, 1)]
Clustering on TRILL#
The TRILL model presented in “Towards Learning a Universal Non-Semantic Representation of Speech”. It exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain (speech emotion recognition, language identification, etc). It is trained on publicly-available AudioSet, https://tfhub.dev/google/nonsemantic-speech-benchmark/trill/3
[8]:
import tensorflow_hub as hub
module = hub.load('https://tfhub.dev/google/nonsemantic-speech-benchmark/trill/3')
[47]:
# i think 60ms pretty ok
frames = malaya_speech.generator.frames(y, frame_duration_ms = 30)
len(frames)
[47]:
2000
[48]:
from tqdm import tqdm
arrays = [f.array for f in frames]
embeddings = []
for i in tqdm(range(len(arrays))):
e = module(arrays[i], sample_rate=16000)['embedding']
embeddings.append(e)
100%|██████████| 2000/2000 [01:02<00:00, 32.23it/s]
[49]:
concat = np.concatenate(embeddings, axis = 0)
concat.shape
[49]:
(2000, 512)
[65]:
clusterer = SpectralClusterer(
min_clusters=1,
max_clusters=100,
p_percentile=0.95,
gaussian_blur_sigma=1.0,
thresholding_soft_multiplier = 1.0,
)
[66]:
%%time
cluster_labels = clusterer.predict(l2_normalize(concat))
frames = malaya_speech.arange.arange_frames(concat, y, sr)
results_trill = []
for no, result in enumerate(cluster_labels):
results_trill.append((frames[no], result))
grouped_trill = malaya_speech.group.group_frames(results_trill)
grouped_trill
CPU times: user 16.1 s, sys: 1.43 s, total: 17.5 s
Wall time: 4.28 s
[66]:
[(<malaya_speech.model.frame.Frame at 0x16dacc210>, 0)]
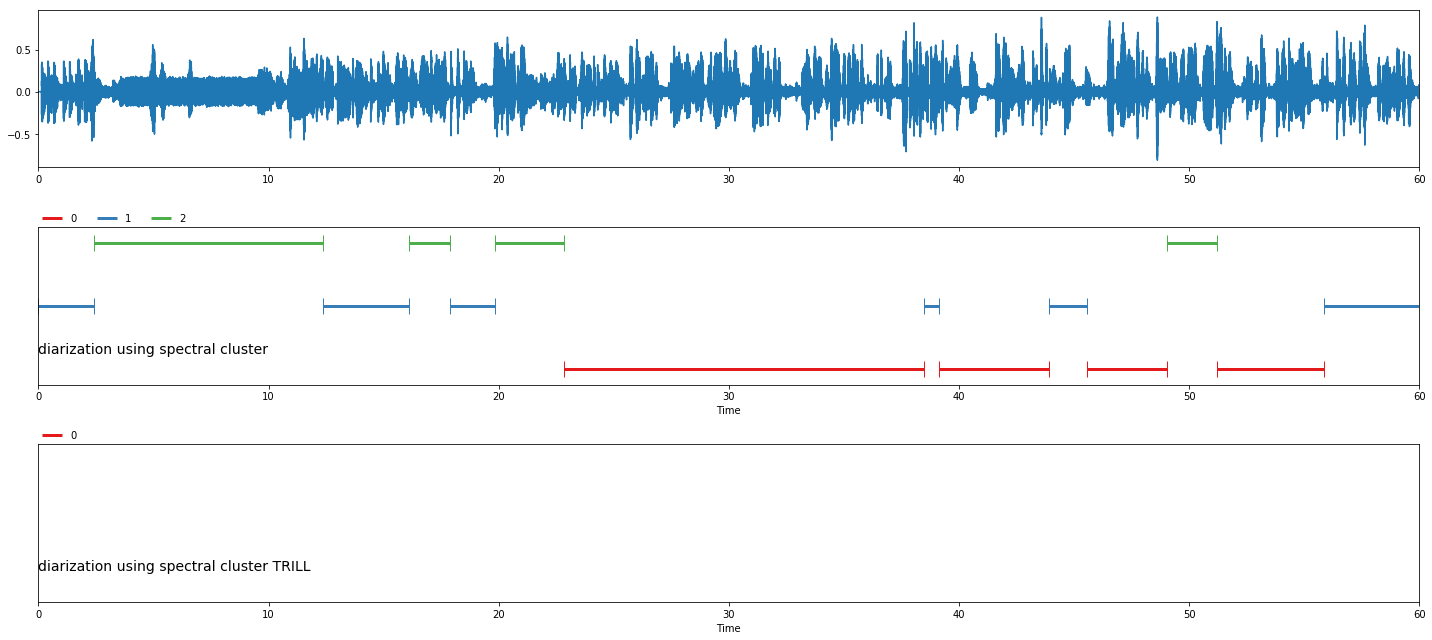
[67]:
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
min_timestamp = min([i[0].timestamp for i in grouped])
max_timestamp = max([i[0].timestamp + i[0].duration for i in grouped])
ax[0].set_xlim((min_timestamp, max_timestamp))
ax[0].plot([i / sr for i in range(len(y))], y)
malaya_speech.extra.visualization.plot_classification(grouped,
'diarization using spectral cluster', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(grouped_trill,
'diarization using spectral cluster TRILL', ax = ax[2],
x_text = 0.01)
fig.tight_layout()
plt.show()
/Users/huseinzolkepli/Documents/malaya-speech/malaya_speech/extra/visualization.py:168: RuntimeWarning: invalid value encountered in true_divide
std = (a - np.min(a)) / (np.max(a) - np.min(a))
[68]:
import IPython.display as ipd
ipd.Audio(grouped[0][0].array, rate = sr)
[68]:
[69]:
ipd.Audio(grouped[1][0].array, rate = sr)
[69]:
[70]:
ipd.Audio(grouped[2][0].array, rate = sr)
[70]:
[71]:
ipd.Audio(grouped[3][0].array, rate = sr)
[71]: