Unsupervised streaming clustering
Contents
Unsupervised streaming clustering#
This tutorial is available as an IPython notebook at malaya-speech/example/unsupervised-streaming-clustering.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
Why streaming?#
Common speaker diarization, the diarization process only able to happened after processed entire audio.
Audio -> chunks -> each chunks convert into embedding / features -> clustering.
This is fine when you have a short medium length audio, but when come to long audio, we have to consider streaming algorithm.
Pros streaming clustering#
Speaker name able to determine in real time manner instead need to process entire audio.
Memory save, not required to store entire embedding / features to cluster.
Cons streaming clustering#
size cluster determine by threshold value, and this can be vary for each audio sample.
size cluster not accurate as process the entire audio.
[133]:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = ''
[136]:
filename = 'Toodia Podcast EP #3: "Macam mana nak manage MASA dan WORK LIFE BALANCE ?" (Part 2) [_FXlFtCIFYk].mp3'
url = 'https://www.youtube.com/watch?v=_FXlFtCIFYk&ab_channel=ScorpiusEntertainment'
if not os.path.exists(filename):
import yt_dlp as youtube_dl
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
'no-check-certificate': True
}
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download([url])
Streaming speaker similarity#
class StreamingSpeakerSimilarity:
def __init__(self, similarity_threshold=0.8, agg_function: Callable = np.mean):
"""
Parameters
----------
similarity_threshold: float, optional (default=0.8)
if current voice activity sample similar at least 0.8, we assumed it is from the same speaker.
"""
[39]:
import malaya_speech
from malaya_speech import Pipeline
from malaya_speech.utils.astype import float_to_int
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from malaya_speech.model.clustering import StreamingSpeakerSimilarity
[2]:
data = np.random.rand(3000, 2)
[18]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.8)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 12056.72it/s]
[18]:
<matplotlib.collections.PathCollection at 0x7fe8ec0b47f0>

[19]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.85)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 11154.73it/s]
[19]:
<matplotlib.collections.PathCollection at 0x7fe8ec016be0>
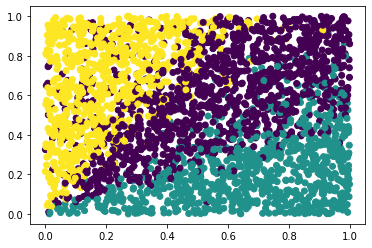
[20]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.9)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 11394.11it/s]
[20]:
<matplotlib.collections.PathCollection at 0x7fe8ec1366d0>

[21]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.95)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 10503.29it/s]
[21]:
<matplotlib.collections.PathCollection at 0x7fe8e47c11f0>
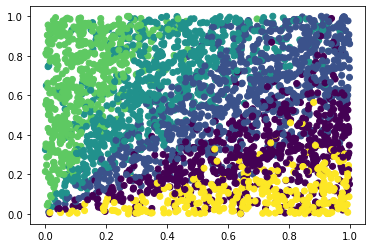
[22]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.99)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 10676.31it/s]
[22]:
<matplotlib.collections.PathCollection at 0x7fe8e472a8b0>

Streaming Kmeans#
https://dl.acm.org/doi/fullHtml/10.1145/3178876.3186124 with removing max_clusters parameter.
class StreamingKMeans:
def __init__(self, threshold=0.1):
"""
Streaming KMeans with no maximum cluster size.
Parameters
----------
threshold: float, optional (default=0.1)
Minimum threshold to consider new cluster.
"""
[23]:
from malaya_speech.model.clustering import StreamingKMeans
[25]:
streaming_model = StreamingKMeans(threshold = 0.3)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 21447.33it/s]
[25]:
<matplotlib.collections.PathCollection at 0x7fe8e4619100>

[26]:
streaming_model = StreamingKMeans(threshold = 0.5)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 37209.39it/s]
[26]:
<matplotlib.collections.PathCollection at 0x7fe8e457a370>

[30]:
streaming_model = StreamingKMeans(threshold = 0.1)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|█████████████████████████████████████| 3000/3000 [00:00<00:00, 3635.40it/s]
[30]:
<matplotlib.collections.PathCollection at 0x7fe8e4473e50>

Streaming Kmeans with maximum cluster size#
Based on https://dl.acm.org/doi/fullHtml/10.1145/3178876.3186124
class StreamingKMeansMaxCluster:
def __init__(self, threshold, max_clusters=5):
"""
Streaming KMeans with maximum cluster size.
Parameters
----------
threshold: float, optional (default=0.1)
Minimum threshold to consider new cluster.
max_clusters: int, optional (default=5)
max cluster size.
"""
[31]:
from malaya_speech.model.clustering import StreamingKMeansMaxCluster
[35]:
streaming_model = StreamingKMeansMaxCluster(threshold = 0.4, max_clusters = 5)
labels = [malaya_speech.diarization.streaming(d, streaming_model, add_speaker_prefix = False) for d in tqdm(data)]
plt.scatter(data[:,0], data[:,1], c=labels)
100%|████████████████████████████████████| 3000/3000 [00:00<00:00, 37500.04it/s]
[35]:
<matplotlib.collections.PathCollection at 0x7fe8e4359160>

Load VAD model#
We are going to use WebRTC VAD model, read more about VAD at https://malaya-speech.readthedocs.io/en/latest/load-vad.html
[41]:
vad_model = malaya_speech.vad.webrtc()
p_vad = Pipeline()
pipeline = (
p_vad.map(lambda x: float_to_int(x, divide_max_abs=False))
.map(vad_model)
)
p_vad.visualize()
[41]:
Diarization Pipeline#
[36]:
speaker_v = malaya_speech.speaker_vector.nemo(model = 'huseinzol05/nemo-titanet_large')
_ = speaker_v.eval()
[166]:
streaming_model = StreamingSpeakerSimilarity(similarity_threshold = 0.7)
[167]:
p_classification = Pipeline()
to_float = p_classification
to_float.map(lambda x: speaker_v([x])[0]) \
.map(lambda x: malaya_speech.diarization.streaming(x, streaming_model), name = 'classification')
p_classification.visualize()
[167]:
[168]:
samples = malaya_speech.streaming.torchaudio.stream(filename,
vad_model = p_vad,
classification_model = p_classification,
segment_length = 320,
realtime_print = True,
min_length = 2.0,
hard_utterence = False)
(speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 1) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 2) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 0) (speaker 0) (speaker 0) (speaker 0) (speaker 3) (speaker 3)
[169]:
len(samples)
[169]:
205
[170]:
import IPython.display as ipd
ipd.Audio(samples[0]['wav_data'], rate = 16000)
[170]:
[171]:
ipd.Audio(samples[3]['wav_data'], rate = 16000)
[171]:
[176]:
vectors = [speaker_v([s['wav_data']])[0] for s in samples]
[178]:
np.array(vectors).shape
[178]:
(205, 192)
[173]:
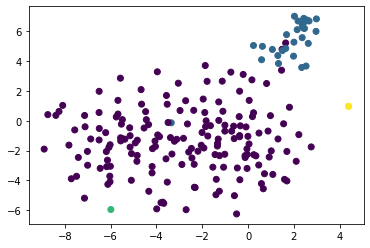
labels = [int(s['classification_model'].split('speaker ')[1]) for s in samples]
labels[:5]
[173]:
[0, 0, 0, 0, 0]
[180]:
from sklearn.manifold import TSNE
x = TSNE().fit_transform(np.array(vectors))
/home/husein/.local/lib/python3.8/site-packages/sklearn/manifold/_t_sne.py:800: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/home/husein/.local/lib/python3.8/site-packages/sklearn/manifold/_t_sne.py:810: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(
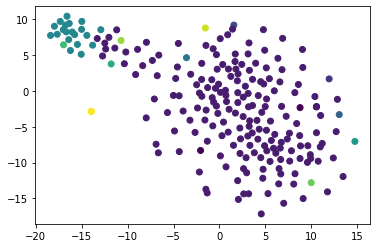
[187]:
plt.scatter(x[:,0], x[:,1], c=labels)
[187]:
<matplotlib.collections.PathCollection at 0x7fe88e665220>
[194]:
streaming_model = StreamingKMeans(threshold = 0.25)
p_classification = Pipeline()
to_float = p_classification
to_float.map(lambda x: speaker_v([x])[0]) \
.map(lambda x: malaya_speech.diarization.streaming(x, streaming_model), name = 'classification')
p_classification.visualize()
[194]:
[195]:
samples = malaya_speech.streaming.torchaudio.stream(filename,
vad_model = p_vad,
classification_model = p_classification,
segment_length = 320,
realtime_print = True,
min_length = 2.0,
hard_utterence = False)
(speaker 0) (speaker 0) (speaker 0) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 2) (speaker 1) (speaker 1) (speaker 1) (speaker 3) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 4) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 5) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 1) (speaker 7) (speaker 8) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 9) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 10) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 6) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 11) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 6) (speaker 6) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 6) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 12) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 6) (speaker 1) (speaker 1) (speaker 1) (speaker 1) (speaker 13) (speaker 13)
[196]:
vectors = [speaker_v([s['wav_data']])[0] for s in samples]
[197]:
import IPython.display as ipd
ipd.Audio(samples[0]['wav_data'], rate = 16000)
[197]:
[198]:
labels = [int(s['classification_model'].split('speaker ')[1]) for s in samples]
labels[:5]
[198]:
[0, 0, 0, 1, 1]
[199]:
x = TSNE().fit_transform(np.array(vectors))
/home/husein/.local/lib/python3.8/site-packages/sklearn/manifold/_t_sne.py:800: FutureWarning: The default initialization in TSNE will change from 'random' to 'pca' in 1.2.
warnings.warn(
/home/husein/.local/lib/python3.8/site-packages/sklearn/manifold/_t_sne.py:810: FutureWarning: The default learning rate in TSNE will change from 200.0 to 'auto' in 1.2.
warnings.warn(
[200]:
plt.scatter(x[:,0], x[:,1], c=labels)
[200]:
<matplotlib.collections.PathCollection at 0x7fe8ecc71160>