
Force Alignment using Transducer
Contents
Force Alignment using Transducer#
Forced alignment is a technique to take an orthographic transcription of an audio file and generate a time-aligned version. In this example, I am going to use Malay and Singlish models.
This tutorial is available as an IPython notebook at malaya-speech/example/force-alignment-transducer.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
[1]:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = ''
[2]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
import IPython.display as ipd
import matplotlib.pyplot as plt
from malaya_speech.utils.aligner import plot_alignments
`pyaudio` is not available, `malaya_speech.streaming.pyaudio` is not able to use.
List available Force Aligner model#
[3]:
malaya_speech.force_alignment.transducer.available_transformer()
[3]:
| Size (MB) | Quantized Size (MB) | Language | |
|---|---|---|---|
| conformer-transducer | 120 | 32.3 | [malay] |
| conformer-transducer-mixed | 120 | 32.3 | [malay, singlish] |
| conformer-transducer-singlish | 120 | 32.3 | [singlish] |
Load Transducer Aligner model#
def transformer(
model: str = 'conformer-transducer',
quantized: bool = False,
**kwargs,
):
"""
Load Encoder-Transducer Aligner model.
Parameters
----------
model : str, optional (default='conformer-transducer')
Check available models at `malaya_speech.force_alignment.transducer.available_transformer()`.
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
Returns
-------
result : malaya_speech.model.transducer.TransducerAligner class
"""
[16]:
model = malaya_speech.force_alignment.transducer.transformer(model = 'conformer-transducer')
singlish_model = malaya_speech.force_alignment.transducer.transformer(model = 'conformer-transducer-singlish')
Load sample#
Malay samples#
[5]:
malay1, sr = malaya_speech.load('speech/example-speaker/shafiqah-idayu.wav')
malay2, sr = malaya_speech.load('speech/example-speaker/haqkiem.wav')
[6]:
texts = ['nama saya shafiqah idayu',
'sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang']
[7]:
ipd.Audio(malay2, rate = sr)
[7]:
Singlish samples#
[8]:
import json
import os
from glob import glob
with open('speech/imda/output.json') as fopen:
data = json.load(fopen)
data
[8]:
{'221931702.WAV': 'wantan mee is a traditional local cuisine',
'221931818.WAV': 'ahmad khan adelene wee chin suan and robert ibbetson',
'221931727.WAV': 'saravanan gopinathan george yeo yong boon and tay kheng soon'}
[9]:
wavs = glob('speech/imda/*.WAV')
wavs
[9]:
['speech/imda/221931727.WAV',
'speech/imda/221931818.WAV',
'speech/imda/221931702.WAV']
[10]:
y, sr = malaya_speech.load(wavs[0])
[11]:
ipd.Audio(y, rate = sr)
[11]:
Predict#
def predict(self, input, transcription: str, sample_rate: int = 16000):
"""
Transcribe input, will return a string.
Parameters
----------
input: np.array
np.array or malaya_speech.model.frame.Frame.
transcription: str
transcription of input audio
sample_rate: int, optional (default=16000)
sample rate for `input`.
Returns
-------
result: Dict[words_alignment, subwords_alignment, subwords, alignment]
"""
Predict Malay#
Our original text is: ‘sebagai pembangkang yang matang dan sejahtera pas akan menghadapi pilihan raya umum dan tidak menumbang kerajaan dari pintu belakang’
[12]:
results = model.predict(malay2, texts[1])
[13]:
results.keys()
[13]:
dict_keys(['words_alignment', 'subwords_alignment', 'subwords', 'alignment'])
[14]:
results['words_alignment']
[14]:
[{'text': 'sebagai',
'start': 0.080000006,
'end': 0.4500000274181366,
'start_t': 2,
'end_t': 11,
'score': 0.9052023},
{'text': 'pembangkang',
'start': 0.56,
'end': 1.050000081062317,
'start_t': 14,
'end_t': 26,
'score': 2.0362883e-07},
{'text': 'yang',
'start': 1.1600001,
'end': 1.29000009059906,
'start_t': 29,
'end_t': 32,
'score': 4.1887343e-08},
{'text': 'matang',
'start': 1.4000001,
'end': 1.6900000667572022,
'start_t': 35,
'end_t': 42,
'score': 2.953248e-08},
{'text': 'dan',
'start': 1.84,
'end': 1.850000033378601,
'start_t': 46,
'end_t': 46,
'score': 7.1333915e-07},
{'text': 'sejahtera',
'start': 2.0400002,
'end': 2.57000018119812,
'start_t': 51,
'end_t': 64,
'score': 1.2432574e-07},
{'text': 'pas',
'start': 2.8400002,
'end': 2.8500001525878904,
'start_t': 71,
'end_t': 71,
'score': 3.5852102e-07},
{'text': 'akan',
'start': 3.1200001,
'end': 3.3300001716613767,
'start_t': 78,
'end_t': 83,
'score': 2.964425e-07},
{'text': 'menghadapi',
'start': 3.4,
'end': 3.8900001144409178,
'start_t': 85,
'end_t': 97,
'score': 3.9114713e-08},
{'text': 'pilihan',
'start': 4.04,
'end': 4.410000095367431,
'start_t': 101,
'end_t': 110,
'score': 2.4833315e-07},
{'text': 'raya',
'start': 4.5600004,
'end': 4.810000190734863,
'start_t': 114,
'end_t': 120,
'score': 4.4663313e-09},
{'text': 'umum',
'start': 4.88,
'end': 5.13000036239624,
'start_t': 122,
'end_t': 128,
'score': 1.7249492e-06},
{'text': 'dan',
'start': 5.32,
'end': 5.330000171661377,
'start_t': 132,
'end_t': 133,
'score': 0.80454177},
{'text': 'tidak',
'start': 5.5200005,
'end': 5.770000228881836,
'start_t': 137,
'end_t': 144,
'score': 3.1422994e-07},
{'text': 'menumbang',
'start': 5.84,
'end': 6.210000286102295,
'start_t': 145,
'end_t': 155,
'score': 3.1152708e-06},
{'text': 'kerajaan',
'start': 6.32,
'end': 6.85000015258789,
'start_t': 157,
'end_t': 171,
'score': 1.8066073e-07},
{'text': 'dari',
'start': 7.0400004,
'end': 7.250000247955322,
'start_t': 175,
'end_t': 181,
'score': 9.301943e-08},
{'text': 'pintu',
'start': 7.32,
'end': 7.530000457763672,
'start_t': 182,
'end_t': 188,
'score': 1.2240405e-07},
{'text': 'belakang',
'start': 7.6400003,
'end': 8.01,
'start_t': 190,
'end_t': 199,
'score': 1.679165e-08}]
[18]:
results['alignment'].shape
[18]:
(205, 51)
[15]:
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111)
ax.set_title('Alignment steps')
im = ax.imshow(
results['alignment'].T,
aspect='auto',
origin='lower',
interpolation='none')
ax.set_yticks(range(len(results['subwords'])))
labels = [item.get_text() for item in ax.get_yticklabels()]
ax.set_yticklabels(results['subwords'])
fig.colorbar(im, ax=ax)
xlabel = 'Encoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Decoder timestep')
plt.tight_layout()
plt.show()
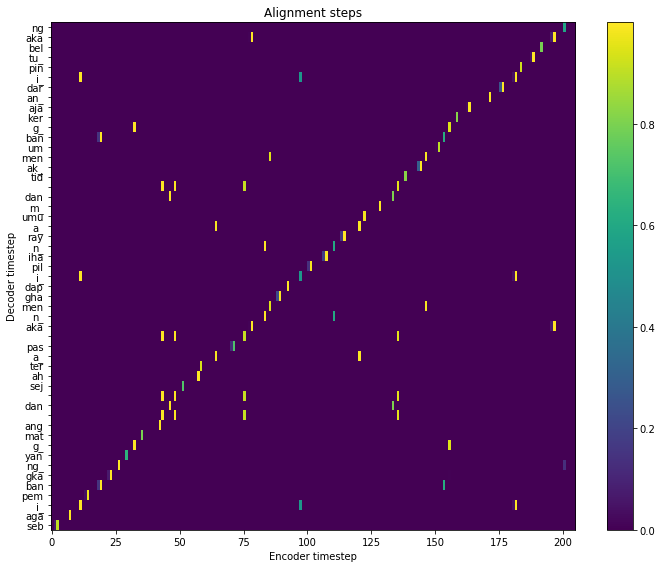
Plot alignment#
def plot_alignments(
alignment,
subs_alignment,
words_alignment,
waveform,
separator: str = ' ',
sample_rate: int = 16000,
figsize: tuple = (16, 9),
plot_score_char: bool = False,
plot_score_word: bool = True,
):
"""
plot alignment.
Parameters
----------
alignment: np.array
usually `alignment` output.
subs_alignment: list
usually `chars_alignment` or `subwords_alignment` output.
words_alignment: list
usually `words_alignment` output.
waveform: np.array
input audio.
separator: str, optional (default=' ')
separator between words, only useful if `subs_alignment` is character based.
sample_rate: int, optional (default=16000)
figsize: tuple, optional (default=(16, 9))
figure size for matplotlib `figsize`.
plot_score_char: bool, optional (default=False)
plot score on top of character plots.
plot_score_word: bool, optional (default=True)
plot score on top of word plots.
"""
[16]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['subwords_alignment'],
words_alignment = results['words_alignment'],
waveform = malay2,
sample_rate = 16000,
figsize = (16, 9))
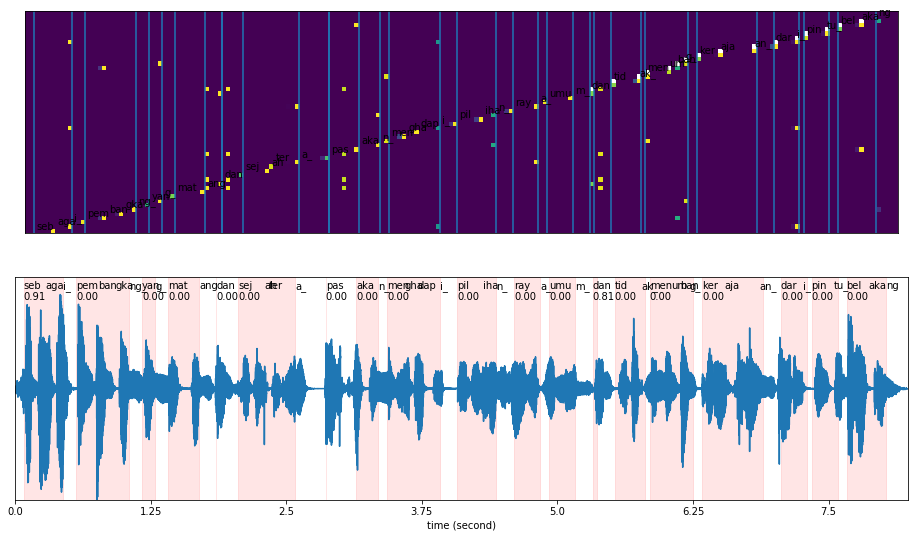
Predict Singlish#
Our original text is: ‘saravanan gopinathan george yeo yong boon and tay kheng soon’
[17]:
results = singlish_model.predict(y, data[os.path.split(wavs[0])[1]])
[18]:
results.keys()
[18]:
dict_keys(['words_alignment', 'subwords_alignment', 'subwords', 'alignment'])
[19]:
results['words_alignment']
[19]:
[{'text': 'saravanan',
'start': 0.88000005,
'end': 1.610000023841858,
'start_t': 22,
'end_t': 40,
'score': 0.94088393},
{'text': 'gopinathan',
'start': 1.8000001,
'end': 2.57000018119812,
'start_t': 45,
'end_t': 64,
'score': 6.0184752e-06},
{'text': 'george',
'start': 3.3200002,
'end': 3.5300002193450926,
'start_t': 82,
'end_t': 88,
'score': 5.478903e-07},
{'text': 'yeo',
'start': 3.8000002,
'end': 3.930000076293945,
'start_t': 94,
'end_t': 98,
'score': 2.5098018e-06},
{'text': 'yong',
'start': 4.2000003,
'end': 4.330000171661377,
'start_t': 104,
'end_t': 108,
'score': 3.500748e-08},
{'text': 'boon',
'start': 4.6800003,
'end': 4.890000114440918,
'start_t': 116,
'end_t': 121,
'score': 2.2932095e-07},
{'text': 'and',
'start': 5.7200003,
'end': 5.730000267028808,
'start_t': 142,
'end_t': 142,
'score': 3.3072836e-11},
{'text': 'tay',
'start': 5.9600005,
'end': 6.13000036239624,
'start_t': 148,
'end_t': 152,
'score': 1.12502056e-10},
{'text': 'kheng',
'start': 6.2400002,
'end': 6.410000095367431,
'start_t': 155,
'end_t': 159,
'score': 1.0052141e-05},
{'text': 'soon',
'start': 6.5600004,
'end': 6.730000267028808,
'start_t': 163,
'end_t': 167,
'score': 1.3059956e-07}]
[20]:
results['subwords_alignment']
[20]:
[{'text': 'sa',
'start': 0.88000005,
'end': 0.8900000548362732,
'start_t': 22,
'end_t': 22,
'score': 0.94088393},
{'text': 'ra',
'start': 1.0400001,
'end': 1.050000081062317,
'start_t': 26,
'end_t': 26,
'score': 0.84687364},
{'text': 'va',
'start': 1.1600001,
'end': 1.1700000858306885,
'start_t': 29,
'end_t': 29,
'score': 0.60696745},
{'text': 'na',
'start': 1.36,
'end': 1.3700000143051148,
'start_t': 34,
'end_t': 34,
'score': 0.6394495},
{'text': 'n_',
'start': 1.6,
'end': 1.610000023841858,
'start_t': 40,
'end_t': 40,
'score': 0.98067147},
{'text': 'go',
'start': 1.8000001,
'end': 1.8100000715255737,
'start_t': 45,
'end_t': 45,
'score': 0.9976705},
{'text': 'pin',
'start': 1.96,
'end': 1.9700000381469727,
'start_t': 49,
'end_t': 49,
'score': 0.9974341},
{'text': 'at',
'start': 2.2800002,
'end': 2.2900002098083494,
'start_t': 57,
'end_t': 57,
'score': 0.9913681},
{'text': 'han',
'start': 2.5600002,
'end': 2.57000018119812,
'start_t': 64,
'end_t': 64,
'score': 0.996283},
{'text': ' ',
'start': 2.68,
'end': 2.690000066757202,
'start_t': 67,
'end_t': 67,
'score': 0.9810955},
{'text': 'ge',
'start': 3.3200002,
'end': 3.3300001716613767,
'start_t': 82,
'end_t': 83,
'score': 0.6300451},
{'text': 'or',
'start': 3.44,
'end': 3.4500000572204588,
'start_t': 85,
'end_t': 86,
'score': 0.9505915},
{'text': 'ge_',
'start': 3.5200002,
'end': 3.5300002193450926,
'start_t': 87,
'end_t': 88,
'score': 0.8043924},
{'text': 'ye',
'start': 3.8000002,
'end': 3.810000190734863,
'start_t': 94,
'end_t': 95,
'score': 0.9639667},
{'text': 'o_',
'start': 3.92,
'end': 3.930000076293945,
'start_t': 97,
'end_t': 98,
'score': 0.5974649},
{'text': 'y',
'start': 4.2000003,
'end': 4.210000286102295,
'start_t': 104,
'end_t': 105,
'score': 0.9869826},
{'text': 'ong',
'start': 4.32,
'end': 4.330000171661377,
'start_t': 107,
'end_t': 108,
'score': 0.9961731},
{'text': ' ',
'start': 4.44,
'end': 4.450000057220459,
'start_t': 110,
'end_t': 111,
'score': 0.80661505},
{'text': 'boo',
'start': 4.6800003,
'end': 4.690000305175781,
'start_t': 116,
'end_t': 117,
'score': 0.956694},
{'text': 'n_',
'start': 4.88,
'end': 4.890000114440918,
'start_t': 121,
'end_t': 121,
'score': 0.0348869},
{'text': 'and',
'start': 5.7200003,
'end': 5.730000267028808,
'start_t': 142,
'end_t': 142,
'score': 0.021826578},
{'text': ' ',
'start': 5.84,
'end': 5.85000015258789,
'start_t': 145,
'end_t': 145,
'score': 0.25638258},
{'text': 'ta',
'start': 5.9600005,
'end': 5.970000514984131,
'start_t': 148,
'end_t': 148,
'score': 0.1680403},
{'text': 'y_',
'start': 6.1200004,
'end': 6.13000036239624,
'start_t': 152,
'end_t': 152,
'score': 0.023210837},
{'text': 'k',
'start': 6.2400002,
'end': 6.250000247955322,
'start_t': 155,
'end_t': 155,
'score': 4.984564e-08},
{'text': 'he',
'start': 6.36,
'end': 6.370000133514404,
'start_t': 158,
'end_t': 158,
'score': 0.35505524},
{'text': 'ng_',
'start': 6.4,
'end': 6.410000095367431,
'start_t': 159,
'end_t': 159,
'score': 6.964538e-05},
{'text': 'so',
'start': 6.5600004,
'end': 6.570000419616699,
'start_t': 163,
'end_t': 163,
'score': 0.0035900134},
{'text': 'on',
'start': 6.7200003,
'end': 6.730000267028808,
'start_t': 167,
'end_t': 167,
'score': 0.0011258913}]
[21]:
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111)
ax.set_title('Alignment steps')
im = ax.imshow(
results['alignment'].T,
aspect='auto',
origin='lower',
interpolation='none')
ax.set_yticks(range(len(results['subwords'])))
labels = [item.get_text() for item in ax.get_yticklabels()]
ax.set_yticklabels(results['subwords'])
fig.colorbar(im, ax=ax)
xlabel = 'Encoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Decoder timestep')
plt.tight_layout()
plt.show()
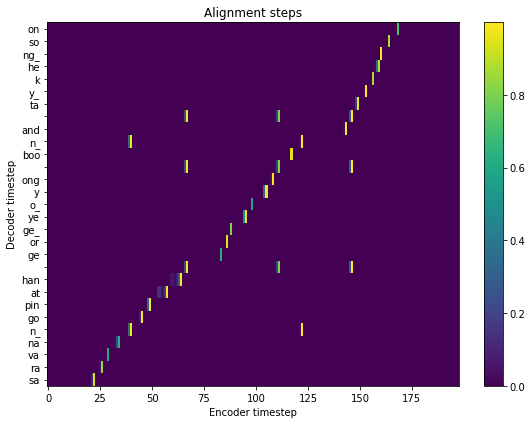
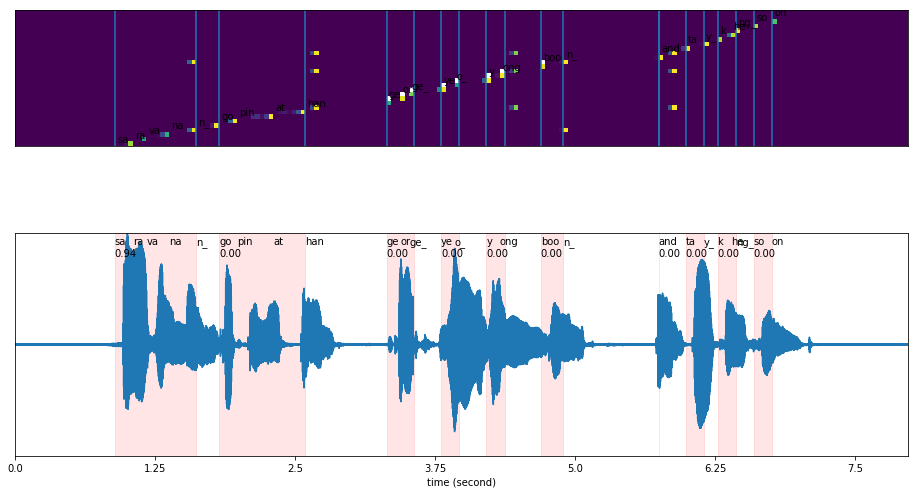
[22]:
plot_alignments(alignment = results['alignment'],
subs_alignment = results['subwords_alignment'],
words_alignment = results['words_alignment'],
waveform = y,
sample_rate = 16000,
figsize = (16, 9))
What if we give wrong transcription?#
[23]:
results = singlish_model.predict(y, 'husein sangat comel')
results
[23]:
{'words_alignment': [{'text': 'huse',
'start': 0.88000005,
'end': 1.1300000047683716,
'start_t': 22,
'end_t': 28,
'score': 1.2089152e-05}],
'subwords_alignment': [{'text': 'hu',
'start': 0.88000005,
'end': 0.8900000548362732,
'start_t': 22,
'end_t': 22,
'score': 3.810164e-07},
{'text': 'se',
'start': 1.12,
'end': 1.1300000047683716,
'start_t': 28,
'end_t': 28,
'score': 1.8430724e-06}],
'subwords': ['hu', 'se'],
'alignment': array([[2.9168962e-07, 1.7420771e-07, 5.1022721e-07, ..., 2.0493981e-07,
7.6540104e-08, 4.9894592e-08],
[4.3830880e-08, 2.8232922e-08, 7.2639679e-08, ..., 3.4464463e-08,
9.9931432e-09, 6.3788850e-09],
[1.2214435e-08, 4.1544523e-09, 1.3750671e-08, ..., 6.1156653e-09,
1.1910063e-09, 1.0353723e-09],
...,
[3.2631554e-08, 1.0152133e-10, 8.5012907e-08, ..., 1.0932835e-07,
7.1939237e-09, 5.8036709e-12],
[6.9185120e-07, 3.0726222e-09, 1.5711264e-06, ..., 1.7108205e-06,
1.9262099e-07, 8.4926129e-11],
[6.6476368e-08, 2.3353811e-10, 3.2911439e-07, ..., 9.6824806e-08,
2.5808857e-08, 1.2000246e-11]], dtype=float32)}
[24]:
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111)
ax.set_title('Alignment steps')
im = ax.imshow(
results['alignment'].T,
aspect='auto',
origin='lower',
interpolation='none')
ax.set_yticks(range(len(results['subwords'])))
labels = [item.get_text() for item in ax.get_yticklabels()]
ax.set_yticklabels(results['subwords'])
fig.colorbar(im, ax=ax)
xlabel = 'Encoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Decoder timestep')
plt.tight_layout()
plt.show()
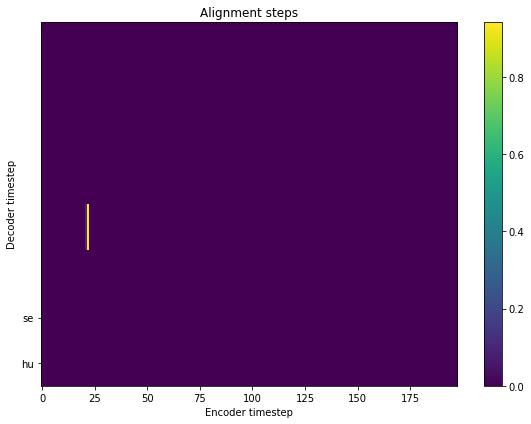
The text output not able to align.