
Super Resolution TFGAN
Contents
Super Resolution TFGAN#
This tutorial is available as an IPython notebook at malaya-speech/example/super-resolution-tfgan.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
Required PyTorch >= 1.10.
Purpose of this module to increase sample rate.
audio -> interpolate 44k sampling rate -> Mel preprocessing -> TFGAN -> output.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
import IPython.display as ipd
[2]:
import logging
logging.basicConfig(level=logging.INFO)
List available TFGAN deep models#
[3]:
malaya_speech.super_resolution.available_tfgan()
INFO:malaya_speech.super_resolution:Only calculate SDR, ISR, SAR on voice sample. Higher is better.
[3]:
| Size (MB) | |
|---|---|
| voicefixer | 489.0 |
| nvsr | 468.0 |
Load TFGAN deep model#
def tfgan(model: str = 'voicefixer', **kwargs):
"""
Load TFGAN based Speech Resolution.
Parameters
----------
model : str, optional (default='voicefixer')
Model architecture supported. Allowed values:
* ``'voicefixer'`` - originally from https://github.com/haoheliu/voicefixer.
* ``'nvsr'`` - originally from https://github.com/haoheliu/ssr_eval/tree/main/examples/NVSR.
Returns
-------
result : malaya_speech.torch_model.super_resolution.VoiceFixer
"""
[4]:
model = malaya_speech.super_resolution.tfgan(model = 'voicefixer')
INFO:malaya_boilerplate.huggingface:downloading frozen huseinzol05/VoiceFixer/model.pth
INFO:malaya_boilerplate.huggingface:downloading frozen huseinzol05/TFGAN/model.pth
Important factor#
Currently TFGAN Super Resolution only able to upsample to 44100 sampling rate, so if you have lower sampling rate, interpolate the audio with 44100 sampling rate and predict using the model
Predict#
def predict(self, input, remove_higher_frequency: bool = True):
"""
Parameters
----------
input: np.array
np.array or malaya_speech.model.frame.Frame,
must an audio with 44100 sampling rate.
remove_higher_frequency: bool, optional (default = True)
Remove high frequency before neural upsampling.
Returns
-------
result: np.array
"""
[5]:
sr = 44100
lower_sr = 8000
[6]:
original_y, _ = malaya_speech.load('speech/44k/test-0.wav', sr = sr)
original_y = original_y[: sr * 4]
len(original_y) / sr
[6]:
4.0
[7]:
ipd.Audio(original_y, rate = sr)
[7]:
[8]:
y, sr_ = malaya_speech.load('speech/44k/test-0.wav', sr = lower_sr)
y = malaya_speech.resample(y, lower_sr, sr)
y = y[:sr * 4]
ipd.Audio(y, rate = sr)
[8]:
[9]:
%%time
output = model(y)
ipd.Audio(output, rate = sr)
CPU times: user 13.6 s, sys: 3.52 s, total: 17.1 s
Wall time: 4.97 s
[9]:
[10]:
import librosa
import matplotlib.pyplot as plt
[11]:
sampling_rate = 44100
fft_size = 2048
hop_size = 256
win_length = None
window = 'hann'
num_mels = 128
fmin = 0
fmax = None
mel_basis = librosa.filters.mel(
sr=sampling_rate,
n_fft=fft_size,
n_mels=num_mels,
fmin=fmin,
fmax=fmax,
)
[12]:
D = librosa.stft(
original_y,
n_fft=fft_size,
hop_length=hop_size,
win_length=win_length,
window=window,
pad_mode='reflect',
)
S, _ = librosa.magphase(D)
mel = np.log10(np.maximum(np.dot(mel_basis, S), 1e-10)).T
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Original Mel-Spectrogram')
im = ax1.imshow(np.rot90(mel), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
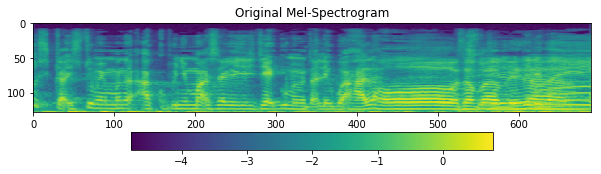
[13]:
D = librosa.stft(
output,
n_fft=fft_size,
hop_length=hop_size,
win_length=win_length,
window=window,
pad_mode='reflect',
)
S, _ = librosa.magphase(D)
mel = np.log10(np.maximum(np.dot(mel_basis, S), 1e-10)).T
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('voicefixer Mel-Spectrogram')
im = ax1.imshow(np.rot90(mel), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
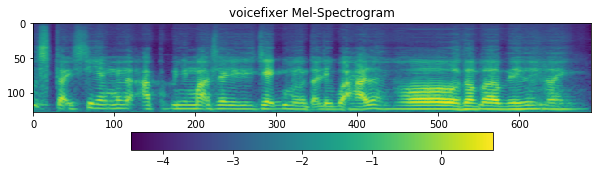
[14]:
D = librosa.stft(
y,
n_fft=fft_size,
hop_length=hop_size,
win_length=win_length,
window=window,
pad_mode='reflect',
)
S, _ = librosa.magphase(D)
mel = np.log10(np.maximum(np.dot(mel_basis, S), 1e-10)).T
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
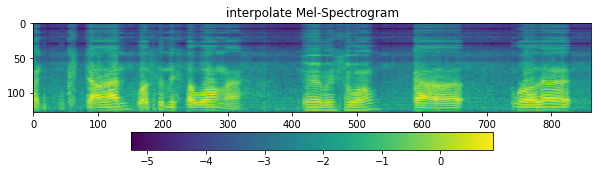
ax1.set_title('interpolate Mel-Spectrogram')
im = ax1.imshow(np.rot90(mel), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
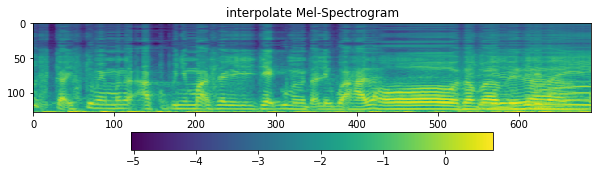
Try more examples#
[15]:
y, sr_ = malaya_speech.load('speech/call-centre/1.wav', sr = 44100)
y = y[sr_ * 5 :sr_ * 10]
sr_
[15]:
44100
[16]:
ipd.Audio(y, rate = sr_)
[16]:
[17]:
%%time
output = model(y)
ipd.Audio(output, rate = sr)
CPU times: user 18.8 s, sys: 5.37 s, total: 24.2 s
Wall time: 7.6 s
[17]:
[18]:
D = librosa.stft(
output,
n_fft=fft_size,
hop_length=hop_size,
win_length=win_length,
window=window,
pad_mode='reflect',
)
S, _ = librosa.magphase(D)
mel = np.log10(np.maximum(np.dot(mel_basis, S), 1e-10)).T
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('output 256 Mel-Spectrogram')
im = ax1.imshow(np.rot90(mel), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
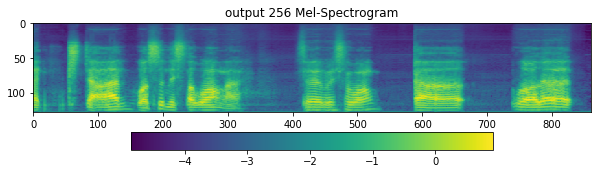
[19]:
D = librosa.stft(
y,
n_fft=fft_size,
hop_length=hop_size,
win_length=win_length,
window=window,
pad_mode='reflect',
)
S, _ = librosa.magphase(D)
mel = np.log10(np.maximum(np.dot(mel_basis, S), 1e-10)).T
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('interpolate Mel-Spectrogram')
im = ax1.imshow(np.rot90(mel), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
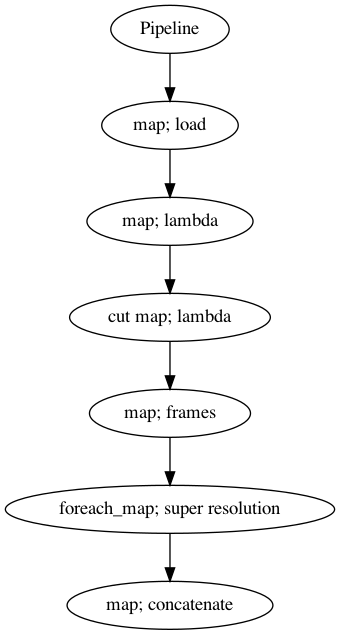
Use Pipeline#
Incase your audio is too long and you do not want to burden your machine. So, you can use malaya-speech Pipeline to split the audio splitted to 3 seconds, predict one-by-one and combine after that.
[36]:
p = Pipeline()
pipeline = (
p.map(malaya_speech.load, sr = sr)
.map(lambda x: x[0])
.map(lambda x: x[sr * 5: sr * 20], name = 'cut')
.map(malaya_speech.generator.frames, frame_duration_ms = 3000, sample_rate = sr)
.foreach_map(model)
.map(np.concatenate)
)
p.visualize()
[36]:
[37]:
%%time
results = p('speech/call-centre/1.wav')
CPU times: user 53.5 s, sys: 14.8 s, total: 1min 8s
Wall time: 19.4 s
[38]:
results.keys()
[38]:
dict_keys(['load', '<lambda>', 'cut', 'frames', 'super-resolution', 'concatenate'])
[39]:
ipd.Audio(results['concatenate'], rate = sr)
[39]:
[40]:
ipd.Audio(results['cut'], rate = sr)
[40]: