
Text-to-Speech Tacotron2
Contents
Text-to-Speech Tacotron2#
Tacotron2, Text to Melspectrogram.
This tutorial is available as an IPython notebook at malaya-speech/example/tts-tacotron2.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
import matplotlib.pyplot as plt
import IPython.display as ipd
Tacotron2 description#
Malaya-speech Tacotron2 will generate melspectrogram with feature size 80.
Use Malaya-speech vocoder to convert melspectrogram to waveform.
List available Tacotron2#
[2]:
malaya_speech.tts.available_tacotron2()
[2]:
| Size (MB) | Quantized Size (MB) | Understand punctuation | Is lowercase | |
|---|---|---|---|---|
| male | 104 | 26.3 | True | True |
| female | 104 | 26.3 | True | True |
| husein | 104 | 26.3 | True | True |
| haqkiem | 104 | 26.3 | True | True |
| female-singlish | 104 | 26.3 | True | True |
| yasmin | 104 | 26.3 | True | False |
| osman | 104 | 26.3 | True | False |
husein voice contributed by Husein-Zolkepli, recorded using low-end microphone in a small room with no reverberation absorber.
haqkiem voice contributed by Haqkiem Hamdan, recorded using high-end microphone in an audio studio.
female-singlish voice contributed by SG National Speech Corpus, recorded using high-end microphone in an audio studio.
Load Tacotron2 model#
Tacotron2 use text normalizer from Malaya, https://malaya.readthedocs.io/en/latest/load-normalizer.html#Load-normalizer,
Make sure you install Malaya version > 4.0 to make it works, to get better speech synthesis, make sure Malaya version > 4.9.1,
pip install malaya -U
def tacotron2(
model: str = 'yasmin',
quantized: bool = False,
pad_to: int = 8,
**kwargs
):
"""
Load Tacotron2 TTS model.
Parameters
----------
model : str, optional (default='yasmin')
Model architecture supported. Allowed values:
* ``'female'`` - Tacotron2 trained on female voice.
* ``'male'`` - Tacotron2 trained on male voice.
* ``'husein'`` - Tacotron2 trained on Husein voice, https://www.linkedin.com/in/husein-zolkepli/
* ``'haqkiem'`` - Tacotron2 trained on Haqkiem voice, https://www.linkedin.com/in/haqkiem-daim/
* ``'yasmin'`` - Tacotron2 trained on female Yasmin voice.
* ``'osman'`` - Tacotron2 trained on male Osman voice.
* ``'female-singlish'`` - Tacotron2 trained on female Singlish voice, https://www.imda.gov.sg/programme-listing/digital-services-lab/national-speech-corpus
quantized : bool, optional (default=False)
if True, will load 8-bit quantized model.
Quantized model not necessary faster, totally depends on the machine.
pad_to : int, optional (default=8)
size of pad character with 0. Increase can stable up prediction on short sentence, we trained on 8.
Returns
-------
result : malaya_speech.model.synthesis.Tacotron class
"""
[31]:
female = malaya_speech.tts.tacotron2(model = 'female')
male = malaya_speech.tts.tacotron2(model = 'male')
husein = malaya_speech.tts.tacotron2(model = 'husein')
haqkiem = malaya_speech.tts.tacotron2(model = 'haqkiem')
female_singlish = malaya_speech.tts.tacotron2(model = 'female-singlish')
INFO:root:running tts/tacotron2-female using device /device:CPU:0
INFO:root:running tts/tacotron2-male using device /device:CPU:0
INFO:root:running tts/tacotron2-husein using device /device:CPU:0
INFO:root:running tts/tacotron2-haqkiem using device /device:CPU:0
INFO:root:running tts/tacotron2-female-singlish using device /device:CPU:0
[10]:
yasmin = malaya_speech.tts.tacotron2(model = 'yasmin')
osman = malaya_speech.tts.tacotron2(model = 'osman')
[5]:
# https://www.sinarharian.com.my/article/115216/BERITA/Politik/Syed-Saddiq-pertahan-Dr-Mahathir
string1 = 'Syed Saddiq berkata mereka seharusnya, mengingati bahawa semasa menjadi Perdana Menteri Pakatan Harapan'
[6]:
string2 = 'husein ketiak wangi dan comel dan kacak bergaya'
Predict#
def predict(self, string):
"""
Change string to Mel.
Parameters
----------
string: str
Returns
-------
result: Dict[string, decoder-output, mel-output, universal-output, alignment]
"""
It only able to predict 1 text for single feed-forward.
[6]:
%%time
r_female = female.predict(string1)
CPU times: user 5.43 s, sys: 2.1 s, total: 7.53 s
Wall time: 7.03 s
[7]:
%%time
r_male = male.predict(string1)
CPU times: user 5.2 s, sys: 2.17 s, total: 7.37 s
Wall time: 6.91 s
[8]:
%%time
r_husein = husein.predict(string1)
CPU times: user 5.34 s, sys: 2.19 s, total: 7.53 s
Wall time: 7 s
[9]:
%%time
r_haqkiem = haqkiem.predict(string1)
CPU times: user 5.22 s, sys: 2.21 s, total: 7.43 s
Wall time: 6.94 s
[10]:
%%time
r_female_singlish = female_singlish.predict(string1)
CPU times: user 5.24 s, sys: 2.25 s, total: 7.49 s
Wall time: 7.23 s
[8]:
%%time
r_yasmin = yasmin.predict(string1)
CPU times: user 6.43 s, sys: 3.05 s, total: 9.49 s
Wall time: 10.5 s
[7]:
%%time
r_osman = osman.predict(string1)
CPU times: user 5.2 s, sys: 2.47 s, total: 7.68 s
Wall time: 7.43 s
[11]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title('Female Attention alignment steps')
im = ax.imshow(
r_female['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
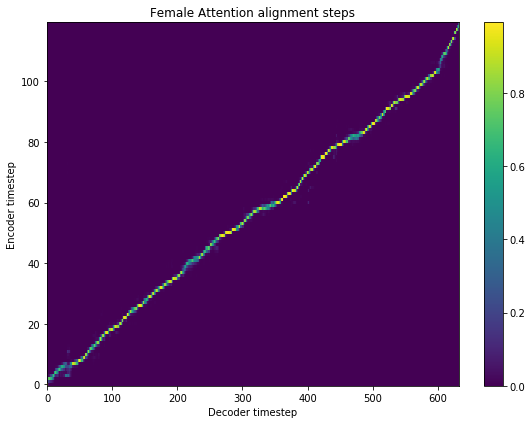
[12]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title('Male Attention alignment steps')
im = ax.imshow(
r_male['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
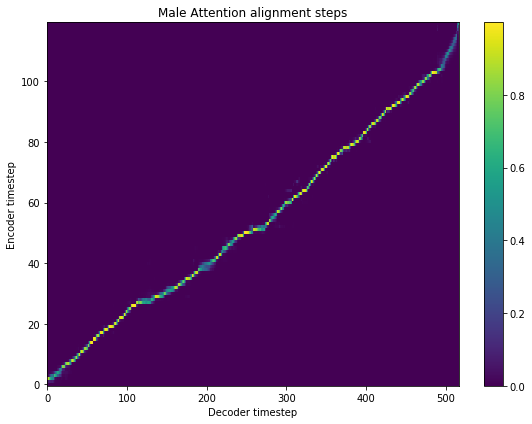
[13]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title('Husein Attention alignment steps')
im = ax.imshow(
r_husein['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
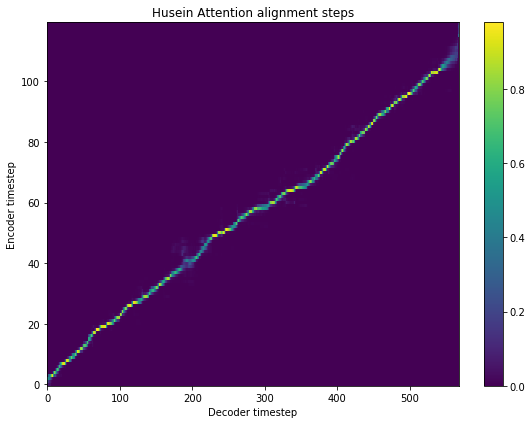
[14]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title('Haqkiem Attention alignment steps')
im = ax.imshow(
r_haqkiem['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
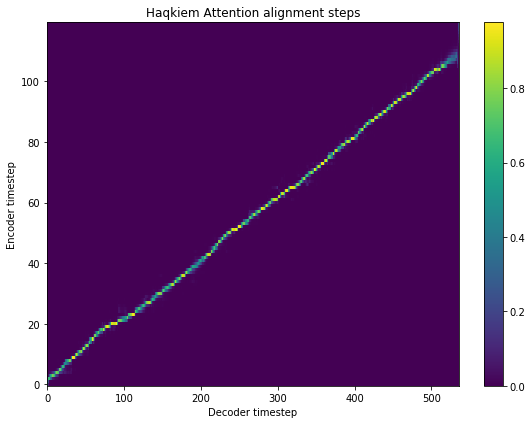
[15]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
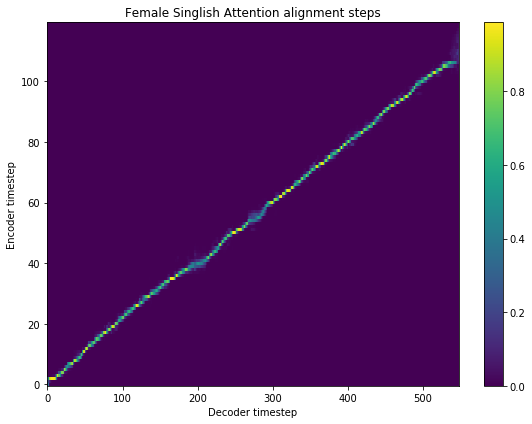
ax.set_title('Female Singlish Attention alignment steps')
im = ax.imshow(
r_female_singlish['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
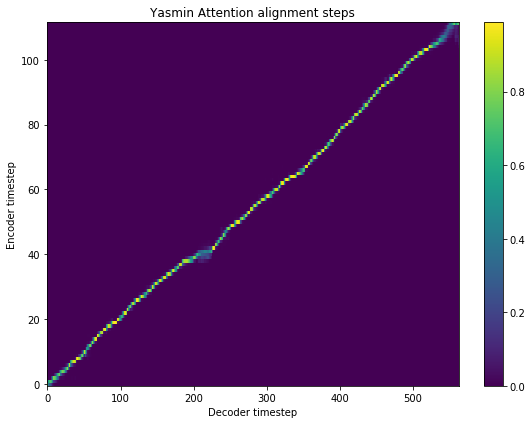
[9]:
fig = plt.figure(figsize = (8, 6))
ax = fig.add_subplot(111)
ax.set_title('Yasmin Attention alignment steps')
im = ax.imshow(
r_yasmin['alignment'],
aspect='auto',
origin='lower',
interpolation='none')
fig.colorbar(im, ax=ax)
xlabel = 'Decoder timestep'
plt.xlabel(xlabel)
plt.ylabel('Encoder timestep')
plt.tight_layout()
plt.show()
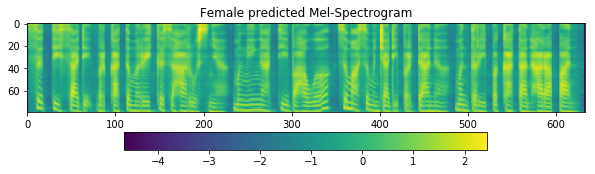
[16]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Female predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_female['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
[17]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Male predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_male['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()

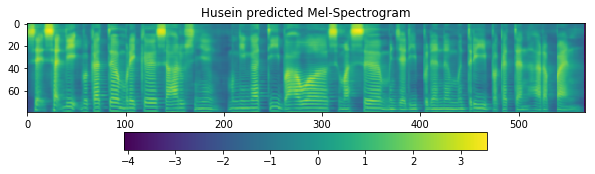
[18]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Husein predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_husein['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
[19]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Haqkiem predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_haqkiem['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
[20]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Female Singlish predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_female_singlish['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
[10]:
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(311)
ax1.set_title('Yasmin Singlish predicted Mel-Spectrogram')
im = ax1.imshow(np.rot90(r_yasmin['mel-output']), aspect='auto', interpolation='none')
fig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)
plt.show()
Load Vocoder model#
There are 2 ways to synthesize melspectrogram output from TTS models,
If you are going to use individual speaker vocoder, make sure the speakers are the same If use female tacotron2, need to use female MelGAN also. Use
mel-outputfrom TTS model. Read more at https://malaya-speech.readthedocs.io/en/latest/load-vocoder.htmlIf you are going to use universal MelGAN, use
universal-outputfrom TTS model. Read more at https://malaya-speech.readthedocs.io/en/latest/load-universal-melgan.html
We prefer individual speaker vocoder, size only 17MB and faster than universal vocoder.
[21]:
vocoder_female = malaya_speech.vocoder.melgan(model = 'female')
vocoder_male = malaya_speech.vocoder.melgan(model = 'male')
vocoder_husein = malaya_speech.vocoder.melgan(model = 'husein')
vocoder_haqkiem = malaya_speech.vocoder.melgan(model = 'haqkiem')
INFO:root:running vocoder-melgan/female using device /device:CPU:0
INFO:root:running vocoder-melgan/male using device /device:CPU:0
INFO:root:running vocoder-melgan/husein using device /device:CPU:0
INFO:root:running vocoder-melgan/haqkiem using device /device:CPU:0
[8]:
universal_melgan = malaya_speech.vocoder.melgan(model = 'universal-1024')
[23]:
y_ = vocoder_female(r_female['mel-output'])
ipd.Audio(y_, rate = 22050)
[23]:
[24]:
y_ = universal_melgan(r_female['universal-output'])
ipd.Audio(y_, rate = 22050)
[24]:
[25]:
y_ = vocoder_male(r_male['mel-output'])
ipd.Audio(y_, rate = 22050)
[25]:
[26]:
y_ = universal_melgan(r_male['universal-output'])
ipd.Audio(y_, rate = 22050)
[26]:
[27]:
y_ = vocoder_husein(r_husein['mel-output'])
ipd.Audio(y_, rate = 22050)
[27]:
[28]:
y_ = universal_melgan(r_husein['universal-output'])
ipd.Audio(y_, rate = 22050)
[28]:
[29]:
y_ = vocoder_haqkiem(r_haqkiem['mel-output'])
ipd.Audio(y_, rate = 22050)
[29]:
[30]:
y_ = universal_melgan(r_haqkiem['universal-output'])
ipd.Audio(y_, rate = 22050)
[30]:
[12]:
y_ = universal_melgan(r_yasmin['universal-output'])
ipd.Audio(y_, rate = 22050)
[12]:
[9]:
y_ = universal_melgan(r_osman['universal-output'])
ipd.Audio(y_, rate = 22050)
[9]: