
Speaker Diarization
Contents
Speaker Diarization#
This tutorial is available as an IPython notebook at malaya-speech/example/diarization.
This module is language independent, so it save to use on different languages. Pretrained models trained on multilanguages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
What is Speaker Diarization#
In one audio sample, we want to know the timestamp for multiple speakers.
[1]:
from malaya_speech import Pipeline
import malaya_speech
import numpy as np
import matplotlib.pyplot as plt
load Speaker Vector#
So to know speakers similarity, we can use speaker vector, just load using malaya_speech.speaker_vector.deep_model. Read more about malaya-speech Speaker Vector at https://malaya-speech.readthedocs.io/en/latest/load-speaker-vector.html
We are going to compare conformer-base and vggvox-v2.
[2]:
model_conformer = malaya_speech.speaker_vector.deep_model('conformer-base')
model_vggvox2 = malaya_speech.speaker_vector.deep_model('vggvox-v2')
Load audio sample#
[3]:
y, sr = malaya_speech.load('speech/video/The-Singaporean-White-Boy.wav')
len(y), sr
[3]:
(1634237, 16000)
[4]:
# just going to take 60 seconds
y = y[:sr * 60]
This audio extracted from https://www.youtube.com/watch?v=HylaY5e1awo&t=2s
Load VAD#
We need to use VAD module to know which parts of the audio sample are speaker activities, read more about VAD at https://malaya-speech.readthedocs.io/en/latest/load-vad.html
[5]:
vad = malaya_speech.vad.deep_model(model = 'vggvox-v2')
[6]:
frames = list(malaya_speech.utils.generator.frames(y, 30, sr))
[7]:
p = Pipeline()
pipeline = (
p.batching(5)
.foreach_map(vad.predict)
.flatten()
)
p.visualize()
[7]:
[8]:
%%time
result = p(frames)
result.keys()
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/librosa/core/spectrum.py:224: UserWarning: n_fft=512 is too small for input signal of length=480
n_fft, y.shape[-1]
CPU times: user 1min 8s, sys: 13.1 s, total: 1min 21s
Wall time: 17.6 s
[8]:
dict_keys(['batching', 'predict', 'flatten'])
[9]:
frames_vad = [(frame, result['flatten'][no]) for no, frame in enumerate(frames)]
grouped_vad = malaya_speech.utils.group.group_frames(frames_vad)
grouped_vad = malaya_speech.utils.group.group_frames_threshold(grouped_vad, threshold_to_stop = 0.3)
[10]:
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, figsize = (15, 3))
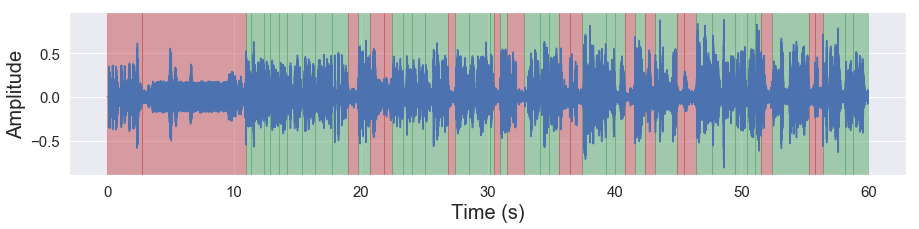
Speaker Similarity#
Simplest technique, calculate similarity,
def speaker_similarity(
vad_results,
speaker_vector,
similarity_threshold: float = 0.8,
norm_function: Callable = None,
return_embedding: bool = False,
):
"""
Speaker diarization using L2-Norm similarity.
Parameters
----------
vad_results: List[Tuple[Frame, label]]
results from VAD.
speaker_vector: callable
speaker vector object.
speaker_change_results: List[Tuple[FRAME, float]], optional (default=None)
results from speaker change module, must in float result.
similarity_threshold: float, optional (default=0.8)
if current voice activity sample similar at least 80%, we assumed it is from the same speaker.
norm_function: Callable, optional(default=None)
normalize function for speaker vectors.
speaker_change_threshold: float, optional (default=0.5)
in one voice activity sample can be more than one speaker, split it using this threshold.
Returns
-------
result : List[Tuple[Frame, label]]
"""
[11]:
result_diarization_conformer = malaya_speech.diarization.speaker_similarity(grouped_vad, model_conformer)
result_diarization_conformer[:5]
[11]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 1'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 2')]
[12]:
result_diarization_vggvox2 = malaya_speech.diarization.speaker_similarity(grouped_vad, model_vggvox2)
result_diarization_vggvox2[:5]
[12]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 1'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 1')]
[13]:
nrows = 2
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_conformer,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
fig.tight_layout()
plt.show()
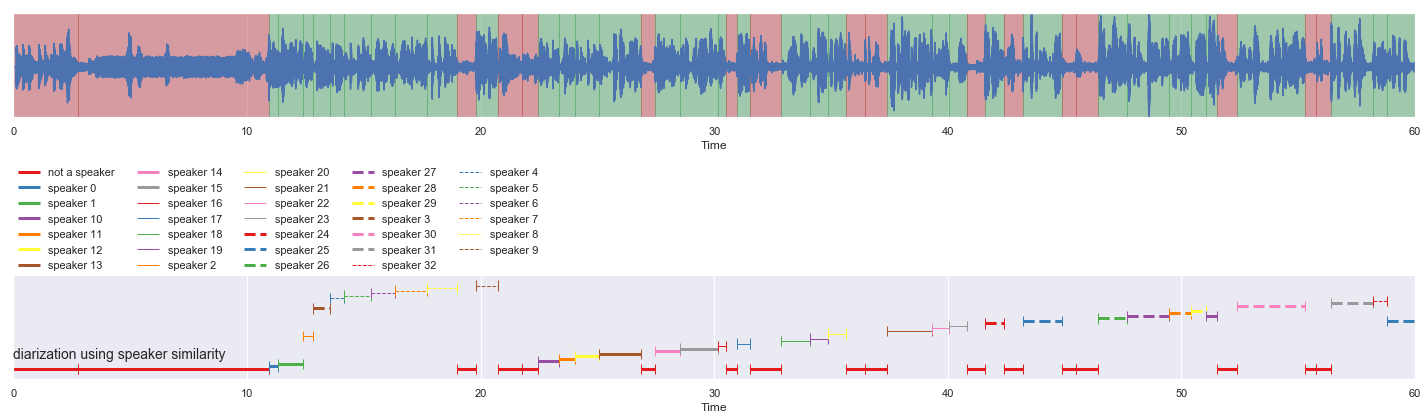
[14]:
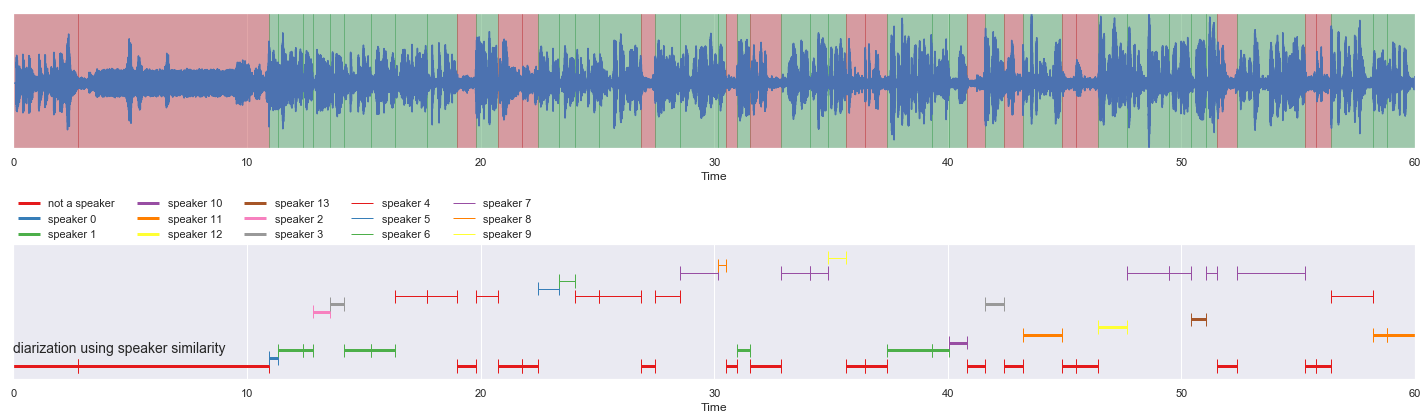
nrows = 2
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_vggvox2,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
fig.tight_layout()
plt.show()
Problem with speaker similarity, speaker vector models are not really consistent, definition of similarity is ambigious among models, 90% similarity from model A might not be same as model B.
So, to solve this problem, we can use Affinity Propagation, a clustering technique.
Affinity Propagation#
Simply a wrapper with distance norm around sklearn,
def affinity_propagation(
vad_results,
speaker_vector,
norm_function: Callable = l2_normalize,
log_distance_metric: str = 'cosine',
damping: float = 0.8,
preference: float = None,
return_embedding = False,
):
"""
Speaker diarization using sklearn Affinity Propagation.
Parameters
----------
vad_results: List[Tuple[Frame, label]]
results from VAD.
speaker_vector: callable
speaker vector object.
norm_function: Callable, optional(default=malaya_speech.utils.dist.l2_normalize)
normalize function for speaker vectors.
log_distance_metric: str, optional (default='cosine')
post distance norm in log scale metrics.
Returns
-------
result : List[Tuple[Frame, label]]
"""
[19]:
result_diarization_ap_conformer = malaya_speech.diarization.affinity_propagation(grouped_vad, model_conformer)
result_diarization_ap_conformer[:5]
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/cluster/_affinity_propagation.py:152: FutureWarning: 'random_state' has been introduced in 0.23. It will be set to None starting from 0.25 which means that results will differ at every function call. Set 'random_state' to None to silence this warning, or to 0 to keep the behavior of versions <0.23.
FutureWarning)
[19]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 5'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 5')]
[16]:
result_diarization_ap_vggvox2 = malaya_speech.diarization.affinity_propagation(grouped_vad, model_vggvox2)
result_diarization_ap_vggvox2[:5]
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/cluster/_affinity_propagation.py:152: FutureWarning: 'random_state' has been introduced in 0.23. It will be set to None starting from 0.25 which means that results will differ at every function call. Set 'random_state' to None to silence this warning, or to 0 to keep the behavior of versions <0.23.
FutureWarning)
[16]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 4')]
[20]:
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_conformer,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_ap_conformer,
'diarization using affinity propagation', ax = ax[2],
x_text = 0.01)
fig.tight_layout()
plt.show()
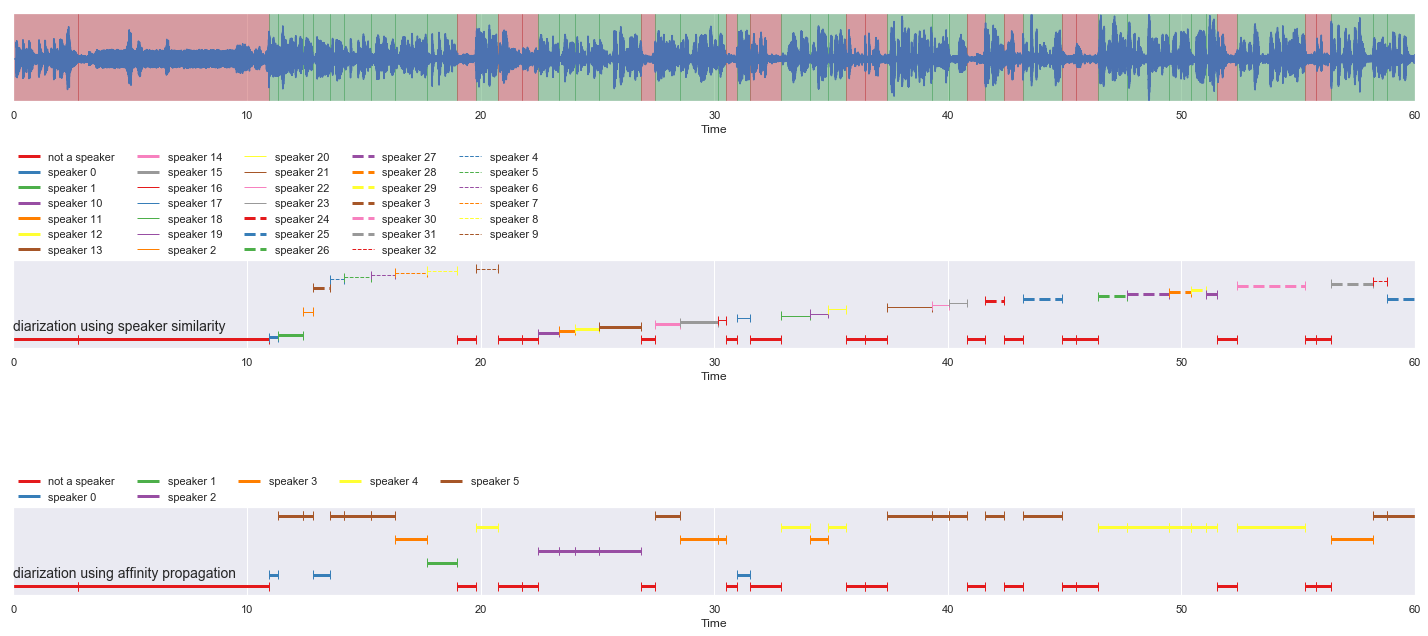
[21]:
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_vggvox2,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_ap_vggvox2,
'diarization using affinity propagation', ax = ax[2],
x_text = 0.01)
fig.tight_layout()
plt.show()
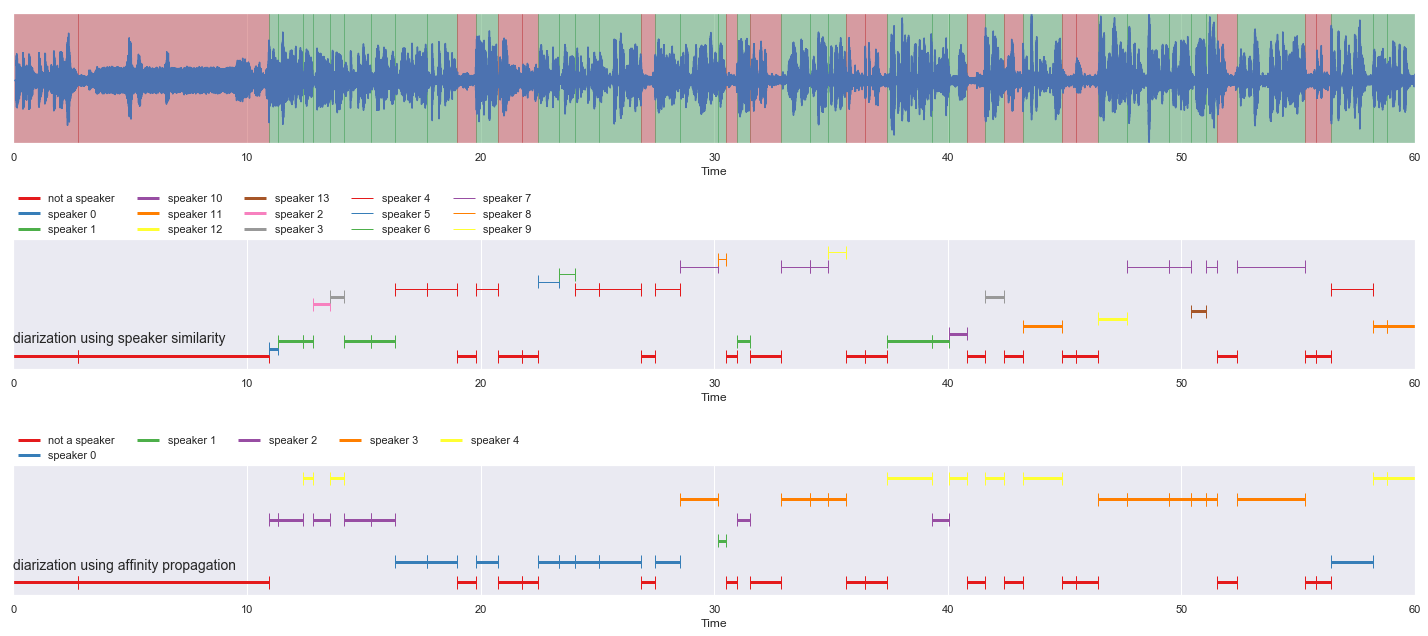
Spectral Clustering#
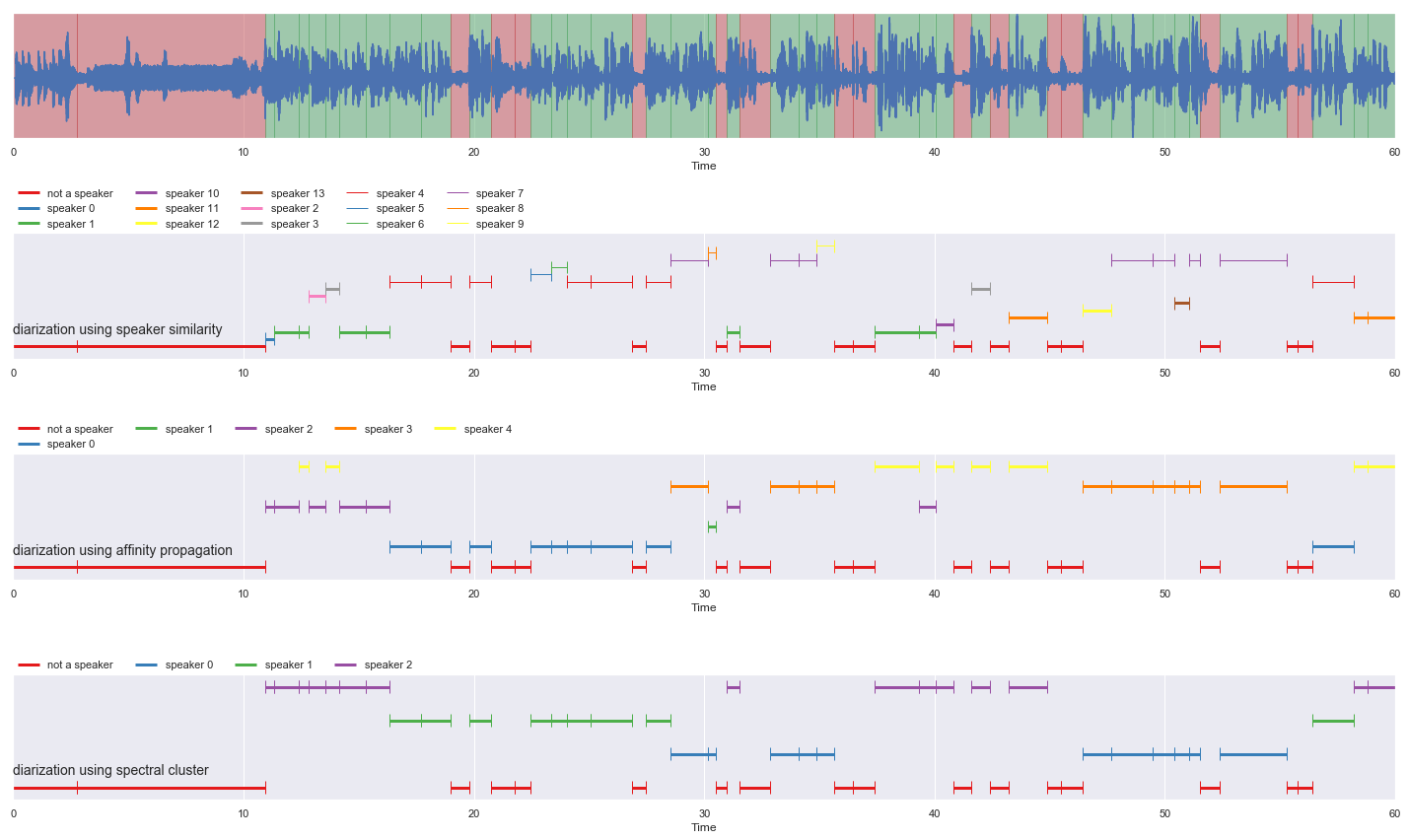
This is a Python re-implementation of the spectral clustering algorithm in the paper Speaker Diarization with LSTM.
So, make sure you already install spectralcluster,
pip install spectralcluster
def spectral_cluster(
vad_results,
speaker_vector,
min_clusters: int = None,
max_clusters: int = None,
norm_function: Callable = l2_normalize,
log_distance_metric: str = None,
return_embedding = False,
**kwargs,
):
"""
Speaker diarization using SpectralCluster, https://github.com/wq2012/SpectralCluster
Parameters
----------
vad_results: List[Tuple[Frame, label]]
results from VAD.
speaker_vector: callable
speaker vector object.
min_clusters: int, optional (default=None)
minimal number of clusters allowed (only effective if not None).
max_clusters: int, optional (default=None)
maximal number of clusters allowed (only effective if not None).
can be used together with min_clusters to fix the number of clusters.
norm_function: Callable, optional(default=malaya_speech.utils.dist.l2_normalize)
normalize function for speaker vectors.
log_distance_metric: str, optional (default=None)
post distance norm in log scale metrics.
Returns
-------
result : List[Tuple[Frame, label]]
"""
[22]:
result_diarization_sc_conformer = malaya_speech.diarization.spectral_cluster(grouped_vad, model_conformer,
min_clusters = 3,
max_clusters = 100)
result_diarization_sc_conformer[:5]
[22]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 0')]
[23]:
result_diarization_sc_vggvox2 = malaya_speech.diarization.spectral_cluster(grouped_vad, model_vggvox2,
min_clusters = 3,
max_clusters = 100)
result_diarization_sc_vggvox2[:5]
[23]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 2')]
[24]:
nrows = 4
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_conformer,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_ap_conformer,
'diarization using affinity propagation', ax = ax[2],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_sc_conformer,
'diarization using spectral cluster', ax = ax[3],
x_text = 0.01)
fig.tight_layout()
plt.show()
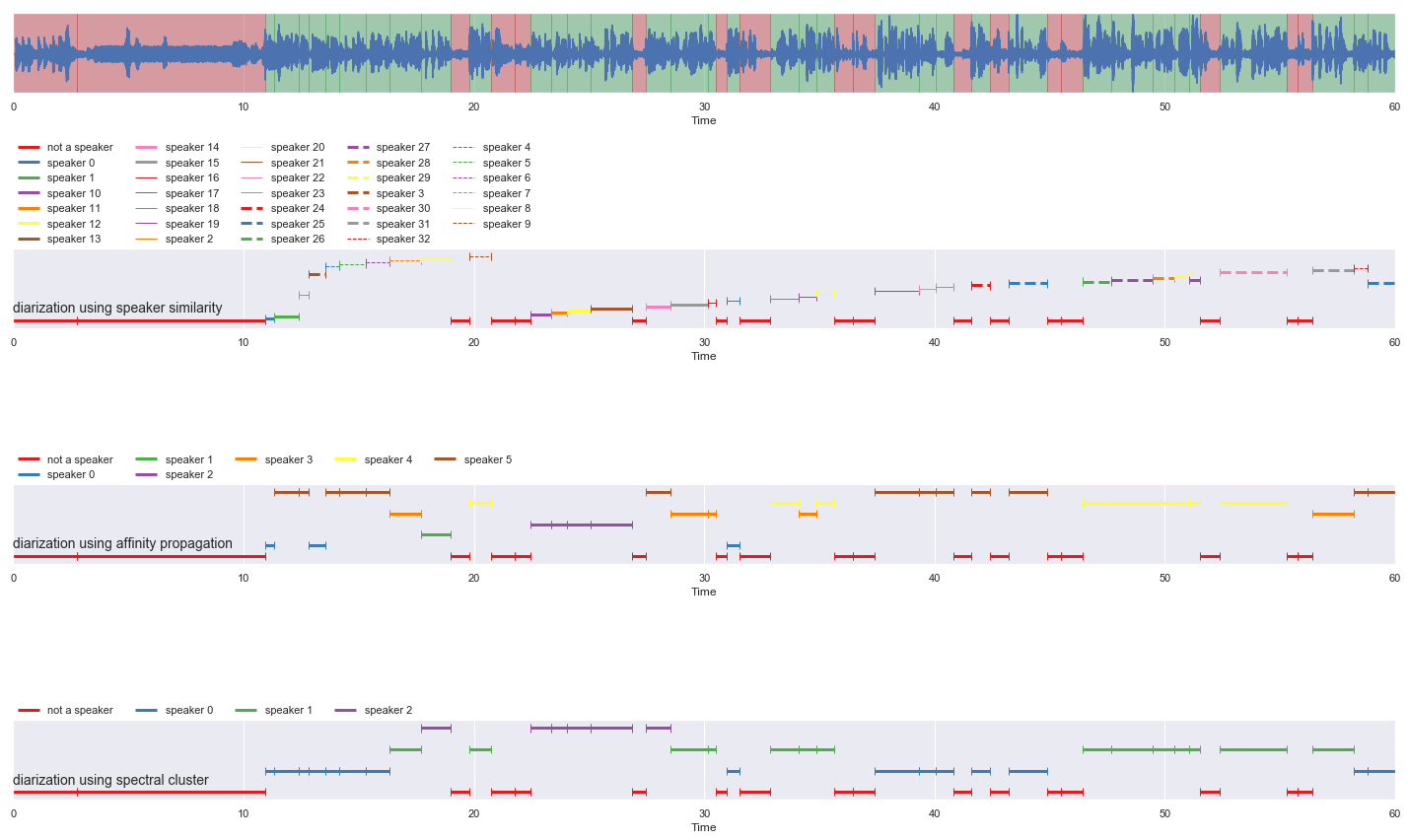
[25]:
nrows = 4
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_vggvox2,
'diarization using speaker similarity', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_ap_vggvox2,
'diarization using affinity propagation', ax = ax[2],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_sc_vggvox2,
'diarization using spectral cluster', ax = ax[3],
x_text = 0.01)
fig.tight_layout()
plt.show()
Static N speakers using sklearn clustering#
Let say you already know N speakers in the audio sample and want to use Kmean algorithm for that.
def n_clustering(
vad_results,
speaker_vector,
model,
norm_function: Callable = l2_normalize,
return_embedding=False,
):
"""
Speaker diarization using any clustering model.
Parameters
----------
vad_results: List[Tuple[Frame, label]]
results from VAD.
speaker_vector: callable
speaker vector object.
model: callable
Prefer any sklearn unsupervised clustering model.
Required `fit_predict` or `apply` method.
norm_function: Callable, optional(default=malaya_speech.utils.dist.l2_normalize)
normalize function for speaker vectors.
log_distance_metric: str, optional (default='cosine')
post distance norm in log scale metrics.
Returns
-------
result : List[Tuple[Frame, label]]
"""
[27]:
from sklearn.cluster import KMeans, SpectralClustering
n_speakers = 3
kmeans = KMeans(n_clusters = n_speakers)
result_diarization_kmeans_conformer = malaya_speech.diarization.n_clustering(grouped_vad, model_conformer,
model = kmeans,
norm_function = lambda x: x)
result_diarization_kmeans_conformer[:5]
[27]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 2'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 2')]
[29]:
spectralclustering = SpectralClustering(n_clusters = n_speakers)
result_diarization_spectralclustering_conformer = malaya_speech.diarization.n_clustering(grouped_vad, model_conformer,
model = spectralclustering,
norm_function = lambda x: x)
result_diarization_spectralclustering_conformer[:5]
[29]:
[(<malaya_speech.model.frame.Frame at 0x15f509390>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc590>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x1634cc3d0>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51be90>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15f51bc50>, 'speaker 0')]
[30]:
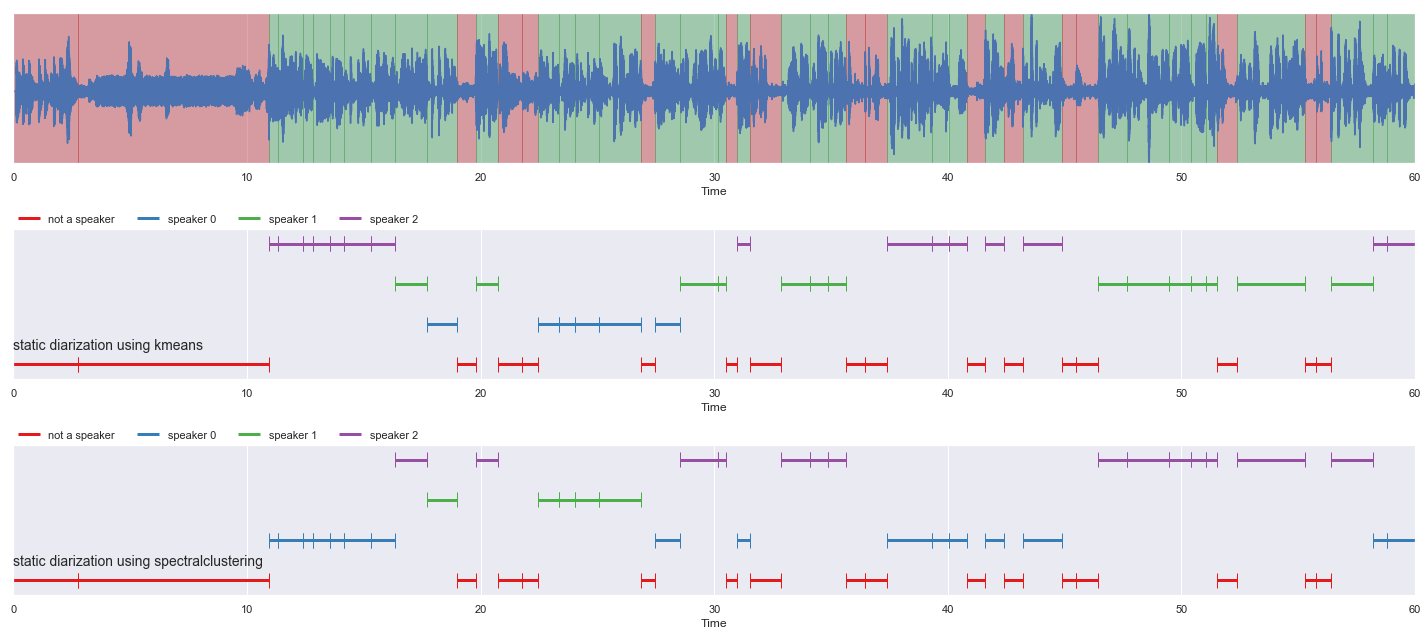
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_kmeans_conformer,
'static diarization using kmeans', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_spectralclustering_conformer,
'static diarization using spectralclustering', ax = ax[2],
x_text = 0.01)
fig.tight_layout()
plt.show()
Use speaker change detection#
Speaker change detection is an important part of speaker diarization systems. It aims at finding the boundaries between speech turns of two different speakers. Read more about Speaker Change at https://malaya-speech.readthedocs.io/en/latest/load-speaker-change.html
[31]:
speakernet = malaya_speech.speaker_change.deep_model('speakernet')
frames_speaker_change = list(malaya_speech.utils.generator.frames(y, 500, sr))
probs_speakernet = [(frame, speakernet.predict_proba([frame])[0, 1]) for frame in frames_speaker_change]
[32]:
nested_grouped_vad = malaya_speech.utils.group.group_frames(grouped_vad)
splitted_speakernet = malaya_speech.speaker_change.split_activities(nested_grouped_vad, probs_speakernet)
[34]:
result_diarization_sc_splitted_conformer = malaya_speech.diarization.spectral_cluster(splitted_speakernet,
model_conformer,
min_clusters = 3,
max_clusters = 100)
result_diarization_sc_splitted_conformer[:5]
[34]:
[(<malaya_speech.model.frame.Frame at 0x194d62450>, 'not a speaker'),
(<malaya_speech.model.frame.Frame at 0x15aecf990>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15aecf810>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15aecf050>, 'speaker 0'),
(<malaya_speech.model.frame.Frame at 0x15aecf610>, 'speaker 0')]
[35]:
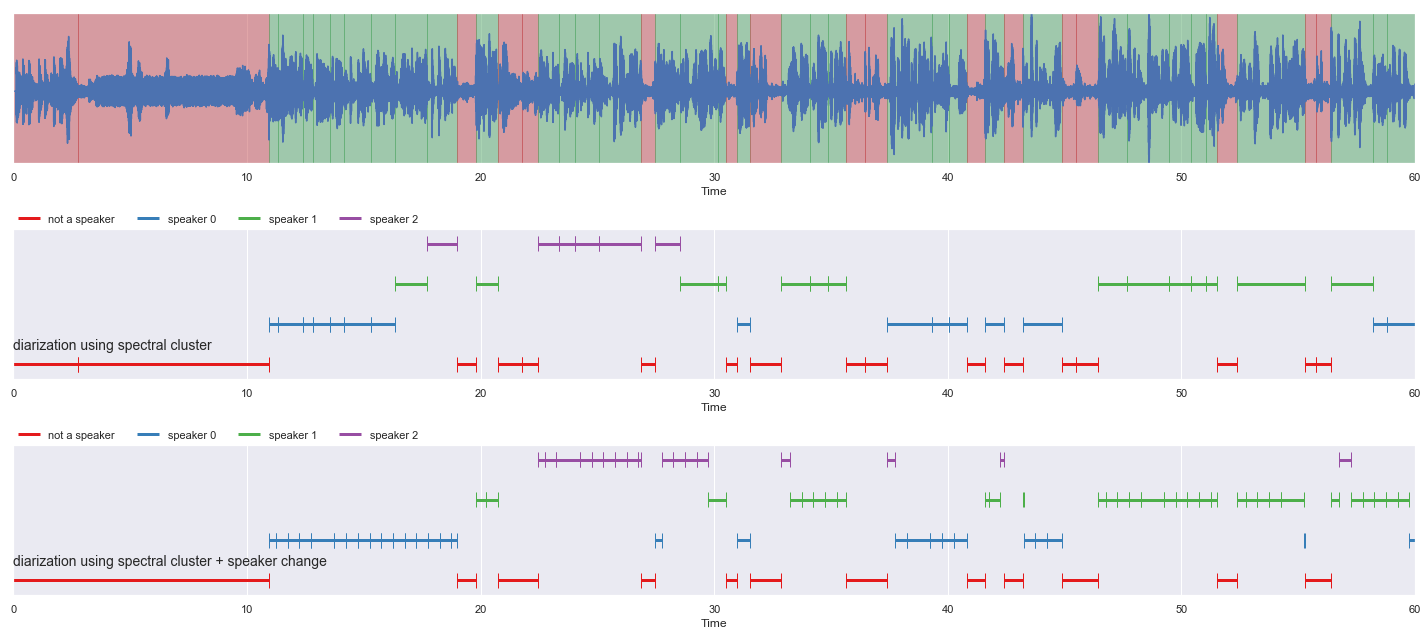
nrows = 3
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(result_diarization_sc_conformer,
'diarization using spectral cluster', ax = ax[1],
x_text = 0.01)
malaya_speech.extra.visualization.plot_classification(result_diarization_sc_splitted_conformer,
'diarization using spectral cluster + speaker change',
ax = ax[2],
x_text = 0.01)
fig.tight_layout()
plt.show()
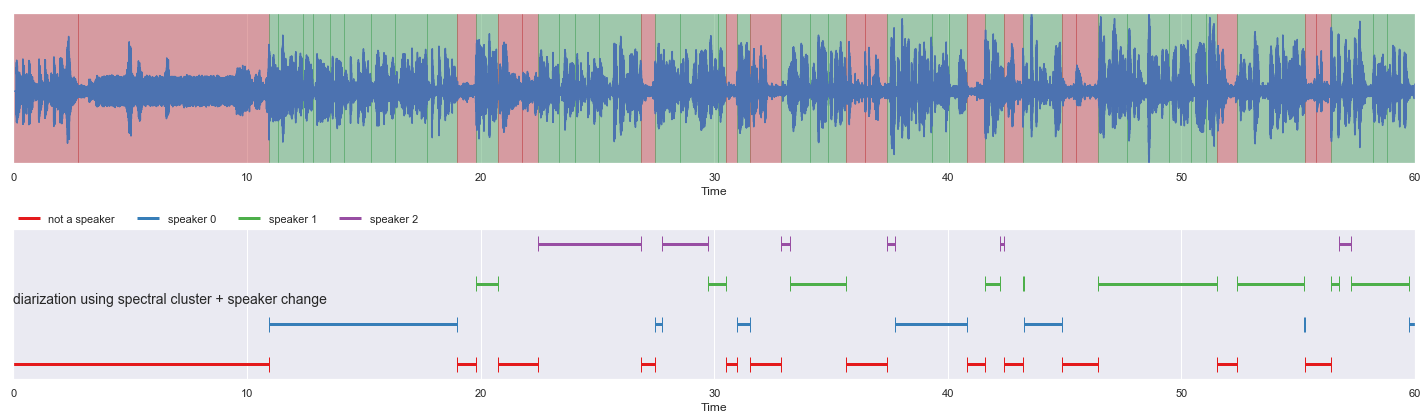
How to get timestamp#
Group multiple frames based on label, this can achieve using
malaya_speech.group.group_frames.
[36]:
grouped = malaya_speech.group.group_frames(result_diarization_sc_splitted_conformer)
nrows = 2
fig, ax = plt.subplots(nrows = nrows, ncols = 1)
fig.set_figwidth(20)
fig.set_figheight(nrows * 3)
malaya_speech.extra.visualization.visualize_vad(y, grouped_vad, sr, ax = ax[0])
malaya_speech.extra.visualization.plot_classification(grouped,
'diarization using spectral cluster + speaker change',
ax = ax[1],
x_text = 0.01, y_text = 0.5)
fig.tight_layout()
plt.show()
Inspect grouped variable.
[37]:
grouped[0]
[37]:
(<malaya_speech.model.frame.Frame at 0x16a3203d0>, 'not a speaker')
malaya_speech.model.frame.Frame stores timestamp and duration attributes.
[38]:
grouped[0][0].timestamp, grouped[0][0].duration, grouped[0][1]
[38]:
(0.0, 10.95000000000002, 'not a speaker')
[39]:
grouped[1][0].timestamp, grouped[1][0].duration, grouped[1][1]
[39]:
(10.949999999999958, 8.040000000000001, 'speaker 0')