
Transcribe long audio
Contents
Transcribe long audio#
This tutorial is available as an IPython notebook at malaya-speech/example/transcribe-long-audio.
This module is not language independent, so it not save to use on different languages. Pretrained models trained on hyperlocal languages.
This is an application of malaya-speech Pipeline, read more about malaya-speech Pipeline at malaya-speech/example/pipeline.
[1]:
import malaya_speech
import numpy as np
from malaya_speech import Pipeline
Let say you want to transcribe a very long audio file, example,
[2]:
from pydub import AudioSegment
import numpy as np
sr = 16000
sound = AudioSegment.from_file('speech/video/70_Peratus_Gaji_Rakyat_Malaysia_Dibelanjakan_Untuk_Barang_Keperluan.mp3')
samples = sound.set_frame_rate(sr).set_channels(1).get_array_of_samples()
[3]:
samples = np.array(samples)
samples = malaya_speech.utils.astype.int_to_float(samples)
[4]:
len(samples) / sr
[4]:
110.106125
110 seconds.
[5]:
import IPython.display as ipd
# just load first 15 seconds
ipd.Audio(samples[:sr * 15], rate = sr)
[5]:
Let’s we try feed into Malaya-Speech ASR model.
Load RNNT model#
Read more about RNNT Speech-to-Text at https://malaya-speech.readthedocs.io/en/latest/load-stt-transducer-model.html
[6]:
model = malaya_speech.stt.deep_transducer(model = 'conformer')
[7]:
model(samples, decoder = 'greedy')
[7]:
'hampir 70 peratus pendapatan bulan anak rakyat negara ini dibelanjakan untuk barang keperluan perumahan dan pengangkutan laporan bank dunia itu juga semakin rendah pendapatan rakyat semakin banyak dibelanjakan mereka untuk makanan ia secara langsung jadikan mereka paling terkesan apabila berlaku kenalkan harga barang untuk golongan kaya pula lagi tinggi pendapatan semakin banyak mereka menghabiskan masa lapang dengan melancong dan ke kelab kelab rekreasi namun yang turut perlu diberi perhatian dalam laporan itu ialah pendapatan rakyat malaysia yang statik ketika kos sara hidup meningkat polis kelantan menasihatkan penduduk negeri tersebut wazpad menghadapi gelombang kedua banjir yang dijangka berlaku 25 dan 26 haribulan ini prometer utamanya yang mempunyai anak kecil agama dan wanita hamil minta sentiasa bersiap sedia tidak akan berpindah kepada bila bila masa manakala di kota tinggi johor lebih 700 penduduk berlindung di lima pusat pemindahan di daerah itu benchanam itu juga telah meragut nyawa pertama di daerah berkenaan selepas seorang lelaki ditemui mati lemas di percaya kibat terjerit sabah kancah kerana program imunisasi tambahan secara besar besaran selepas seorang bayi di tuaran disahkan dijangkiti polio juga merupakan kes pertama di negara ini selepas 27 tahun disahkan bebas daripada faris tersebut salah satu ikon kl itu taman tan siti wangsa akan dibuka semula ahad ini selepas dinaiktaraf dengan kos hampir 100 juta ringgit dan filem jumaji dan slimelmencatat kutipan 15 juta ringgit hanya selepas empat hari ditahankan di malaysia'
As you can see, the output is not really good. The reason why here, we only trained samples less than 20 seconds to reduce memory consumption, so to solve this long problem, we need to split the sample using VAD, can read more at https://malaya-speech.readthedocs.io/en/latest/split-utterances.html
Initate pipeline#
[8]:
vad = malaya_speech.vad.deep_model(model = 'vggvox-v2', quantized = True)
WARNING:root:Load quantized model will cause accuracy drop.
[9]:
p = Pipeline()
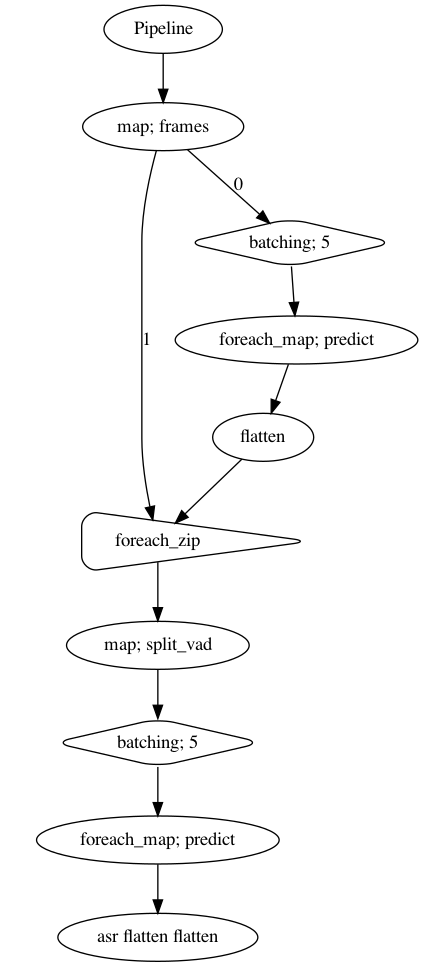
frame = (
p.map(malaya_speech.utils.generator.frames, frame_duration_ms = 30)
)
vad_map = frame.batching(5).foreach_map(vad.predict).flatten()
foreach = frame.foreach_zip(vad_map)
splitted = foreach.map(malaya_speech.split.split_vad)
asr_map = splitted.batching(5).foreach_map(model.predict, decoder = 'greedy').flatten(name = 'asr-flatten')
p.visualize()
[9]:
[10]:
%%time
result = p(samples)
result.keys()
/Users/huseinzolkepli/Documents/tf-1.15/env/lib/python3.7/site-packages/librosa/core/spectrum.py:224: UserWarning: n_fft=512 is too small for input signal of length=480
n_fft, y.shape[-1]
/Users/huseinzolkepli/Documents/tf-1.15/env/lib/python3.7/site-packages/librosa/core/spectrum.py:224: UserWarning: n_fft=512 is too small for input signal of length=98
n_fft, y.shape[-1]
CPU times: user 1min 54s, sys: 27.6 s, total: 2min 21s
Wall time: 29.2 s
[10]:
dict_keys(['frames', 'batching', 'predict', 'flatten', 'foreach_zip', 'split_vad', 'flatten_asr-flatten'])
[11]:
result['flatten_asr-flatten']
[11]:
['hampir 70 peratus pendapatan bulan anak rakyat negara ini dibelanjakan untuk barang keperluan perumahan dan pengangkutan',
'duduk laporan bank dunia itu juga semakin rendah pendapatan rakyat semakin banyak dibelanjakan mereka untuk makanan ia secara langsung jadikan mereka paling terkesan',
'apabila berlaku kenaikan harga barang untuk golongan kaya pula lagi tinggi pendapatan semakin banyak mereka menghabiskan masa lapang dengan melancong dan ke kelab kelab rekreasi',
'namun yang turut perlu diberi perhatian dalam laporan itu ialah pendapatan rakyat malaysia yang statik ketika kos sara hidup meningkat',
'polis kelantan menasihatkan penduduk negeri tersebut waspada menghadapi gelombang kedua banjir',
'ini jangka berlaku 25 dan 26 haribulan ini ramai terutamanya yang mempunyai anak kecil agama dan wanita hamil ini sentiasa bersiap sediam',
'tidak akan berpindah pada bila bila masa manakala di kota tinggi johor',
'lebih 700 penduduk berlindung di lima pusat pemindahan di daerah itu bencana alam itu juga telah meragut nyawa pertama di daerah berkenaan',
'selepas seorang lelaki ditemui mati lemas dipercayai sebab terjatuh dari jeti sabah kelantan program imunisasi tambahan secara besar besaran',
'selepas seorang bayi di tuaran disahkan dijangkiti folio juga merupakan kes pertama di negara ini selepas 27 tahun disahkan bebas daripada faris tersebut',
'assalamualaikum ikon kl itu taman tan siti wangsa akan dibuka semula ahad ini selepas dinaiktaraf dengan kos hampir 100 juta ringgit',
'dan filem jumaat slibhari ditayangkan di malaysia',
'']
[14]:
import IPython.display as ipd
ipd.Audio(result['split_vad'][-4].array, rate = 16000)
[14]: